The world need more and better programmers. Jason Gorman recently wrote this post encouraging people to start offering software apprenticeships, as an alternative to computer science degrees.
He writes:
"our computing education in [the UK] is preparing students for a career in a version of computing most of us don't recognise. Students devote the majority of their time learning theory and skills that they almost certainly won't be applying when they get their first proper job. Computing schools are hopelessly out of touch with the reality of computing in the real world. While employers clamour for TDD or refactoring skills, academics turn their noses up at them and focus on things like formal specification and executable UML and compiler design, along with outdated and thoroughly discredited "software engineering" processes." -- Jason Gorman
Jason ends his post with a call to arms - if you're a good software developer, get yourself an apprentice, and start training them. It's the same message I heard from Dave Hoover when he visited Göteborg recently. I think he also sees a multi-year apprenticeship as a better alternative for training programmers than a computer science degree.
I also recently came across this article, written by a computer science teacher in the US, with the following paragraph:
"I no longer teach programming by teaching the features of the language and asking the students for original compositions in the language. Instead I give them programs that work and ask them to change their behavior. I give them programs that do not work and ask them to repair them. I give them programs and ask them to decompose them. I give them executables and ask them for source, un-commented source and ask for the comments, description, or specification. I let them learn the language the same way that they learned their first language. All tools, tactics and strategies are legitimate. " -- William Hugh Murray
So clearly some academics are teaching in creative ways. Rather than abandoning computer science degrees, might it not be better to improve their content?
One of the things about the XP conference is that it brings together industry and academics, and lets them hear from one another. How to teach programming is a very important topic that is often discussed there. XP2005 for example was held at Sheffield university, where I remember chatting to one of the professors, and being impressed by the way they used eXtreme Programming as part of their undergraduate course.
Another thing that happened at XP2005 was the first coding dojo I attended, and I believe the first one ever held outside of France. It was presented by Laurent Bossavit and Emmanuel Gaillot, founders of the Paris dojo. I was excited to discover a context in which I could improve my practical programming skills, in regular short bursts, alongside a continuing paid job.
So one of the things I do in my new life as an agile testing consultant is to use the coding dojo format to teach people how to program better. We'll do code kata exercises and practice Test Driven Development, Refactoring, and discuss what Clean Code looks like. So far the reaction from professionals I've done this with has been very positive. Lots of people who have been coding for years appreciate the chance to learn new practical skills.
I'm also getting involved in more formal education, this spring I'm teaching a three week course in automated testing, as part of a "Kvalificerad Yyrkesutbildning" in software testing. This is a one year full time course for students wanting to learn a practical skill, as an alternative to going to university and studying a more academic subject. In Sweden you can get a student loan while you're studying this course, and part of the time is spent working in a company gaining on-the-job experience.
I'm starting to plan how I'm going to teach TDD, BDD, and how to use tools like Selenium, Fitnesse, TextTest and Cucumber. I think it's going to be very hands on and practical, but also go into the general principles behind tool choice and writing maintainable automated tests. I'm helping to write a formal syllabus and exam, with criteria for grades awarded.
I guess what I'm trying to say is that I don't like this strand of thought in the Software Craftsmanship movement that wants to abandon formal education. There are lots of ways to train software developers, and apprenticeship isn't without its problems.
I think this is just the sort of thing we'll be discussing at XP2011, where there will be a host of academics and experts from industry. Won't you join us?
Thursday, 16 December 2010
Thursday, 9 December 2010
XP2011
I've just been appointed to the role of Industry Programme Chair for XP2011, which will be held in Madrid in May. I've been to 7 of the previous 11 XP conferences and I am so pleased to be asked to contribute to the success of the conference this year by doing this role.
Rachel Davies is the general chair, and I am really looking forward to working with her and the other organizers. Rachel is one of those people I have met repeatedly at conferences and always has something interesting to contribute. More recently, I read her excellent book on Agile Coaching. I can't remember exactly when I first met her, but I do remember meeting her former colleagues from Connextra, Tim MacKinnon and Steve Freeman. I can still picture them in the small minibus that picked us up from a tiny Italian airport in 2002. It was a hot summers day, and we were driven at high speed along small Sardinian roads to the lovely hotel Calabona by the sea and the historic walled city of Alghero. I remember being so impressed to meet some people who were actually doing eXtreme Programming for real.
There were so many inspirational people at that conference, it was really a turning point in my career. I just found the old conference programme online here, and it brings back so many memories!
I remember sitting by the pool discussing subjects like how to test drive refactoring with Frank Westphal and Steve Freeman. There was a firey keynote from Ken Schwaber encouraging us to start a revolution in software development world. I remember Joshua Kerievsky asking Jutta Eckstein to explain all about how she was doing XP with a team of over 100 people. Following David Parnas' keynote about using a formal test specification language to define requirements I remember Martin Fowler opining about its usefulness or lack of it, (do read his blog post about it).
The colourful personality of Scott Ambler demonstrated his ability to break a plank of wood in two with his bare hands, as some kind of lesson to do with dedication and focus. The conference dinner at Poco Loco really was a little crazy, with a bunch of uncoordinated geeks going for it on the dancefloor while the local band played very loudly. The morning after everyone was rather subdued when listening to Enrico Zaninotto reading his keynote in halting English, relating XP to the history of manufacturing and modern lean ideals. Half the audience was having trouble staying awake which in no way reflected the quality of what he was saying. It was truly inspiring, and Mary and Tom Poppendieck in particular were listening in rapt attention.
Michael Feathers wore a T-shirt saying "Save the LSF", and Geoff and I asked him why he was so interested in platform computing's Load Sharing Facility. It turned out Alan Francis had recently become unemployed and Mike was helping in the campaign to "Save the Lightly Scottish Fellow"!
Laurent Bossavit was going round trying to attract people to his Birds Of a Feather session on the writings of Gerald Weinberger. Erik Lundh was taking about his team in Sweden who had done a complete XP iteration in 2 days when faced with an unexpected deadline. Steven Fraser seemed to be videoing everything and anything, including someone demonstrating the correct way to twirl Italian Spaghetti on a fork. Mike Hill was (as ever) being loud but friendly. Charlie Poole seemed to be full of insightful analogies and comments. Dave Hussman was really friendly too.
It was just fantastic the way the XP community welcomed us in, and particularly Kent Beck's attitude was instrumental in that. My husband Geoff and I presented a poster at the conference with title "One suite of automated tests" based mainly on Geoff's experiences with the tool that was to become TextTest. We turned up on the first day for a workshop about "testing in XP", and Geoff was immediately controversial by saying that he didn't do any unit testing, only this weird text-based testing thing using log comparison. He said he found it so successful that he used it instead of both the XP practices of functional and unit testing. I remember several people being quite dismissive of his ideas.
Later in the conference, Kent Beck made a particular effort to talk to us and we took our picture standing by our poster. Apparently he had been asking people to try to be inclusive and friendly to us after the somewhat negative reaction to our ideas. I think he wanted the newly-forming XP community to be welcoming and to embrace diversity of opinion.

So now I should turn this around and look instead to the future. I'd love it if even half the people I've mentioned in this post found time in their diaries to come to Madrid in May for XP2011. I wouldn't want them to come alone though, there are so many fantastic and inspirational people who have joined the ever-expanding agile community since 2002.
I am every bit as keen now as Kent was then to see that the agile community embraces newcomers, and that the XP conference should provide a space where researchers and practitioners can freely discuss the state of the art. I hope we'll make new friends and business contacts, learn loads, and have fun. Would you like to join us there?
Rachel Davies is the general chair, and I am really looking forward to working with her and the other organizers. Rachel is one of those people I have met repeatedly at conferences and always has something interesting to contribute. More recently, I read her excellent book on Agile Coaching. I can't remember exactly when I first met her, but I do remember meeting her former colleagues from Connextra, Tim MacKinnon and Steve Freeman. I can still picture them in the small minibus that picked us up from a tiny Italian airport in 2002. It was a hot summers day, and we were driven at high speed along small Sardinian roads to the lovely hotel Calabona by the sea and the historic walled city of Alghero. I remember being so impressed to meet some people who were actually doing eXtreme Programming for real.
There were so many inspirational people at that conference, it was really a turning point in my career. I just found the old conference programme online here, and it brings back so many memories!
I remember sitting by the pool discussing subjects like how to test drive refactoring with Frank Westphal and Steve Freeman. There was a firey keynote from Ken Schwaber encouraging us to start a revolution in software development world. I remember Joshua Kerievsky asking Jutta Eckstein to explain all about how she was doing XP with a team of over 100 people. Following David Parnas' keynote about using a formal test specification language to define requirements I remember Martin Fowler opining about its usefulness or lack of it, (do read his blog post about it).
The colourful personality of Scott Ambler demonstrated his ability to break a plank of wood in two with his bare hands, as some kind of lesson to do with dedication and focus. The conference dinner at Poco Loco really was a little crazy, with a bunch of uncoordinated geeks going for it on the dancefloor while the local band played very loudly. The morning after everyone was rather subdued when listening to Enrico Zaninotto reading his keynote in halting English, relating XP to the history of manufacturing and modern lean ideals. Half the audience was having trouble staying awake which in no way reflected the quality of what he was saying. It was truly inspiring, and Mary and Tom Poppendieck in particular were listening in rapt attention.
Michael Feathers wore a T-shirt saying "Save the LSF", and Geoff and I asked him why he was so interested in platform computing's Load Sharing Facility. It turned out Alan Francis had recently become unemployed and Mike was helping in the campaign to "Save the Lightly Scottish Fellow"!
Laurent Bossavit was going round trying to attract people to his Birds Of a Feather session on the writings of Gerald Weinberger. Erik Lundh was taking about his team in Sweden who had done a complete XP iteration in 2 days when faced with an unexpected deadline. Steven Fraser seemed to be videoing everything and anything, including someone demonstrating the correct way to twirl Italian Spaghetti on a fork. Mike Hill was (as ever) being loud but friendly. Charlie Poole seemed to be full of insightful analogies and comments. Dave Hussman was really friendly too.
It was just fantastic the way the XP community welcomed us in, and particularly Kent Beck's attitude was instrumental in that. My husband Geoff and I presented a poster at the conference with title "One suite of automated tests" based mainly on Geoff's experiences with the tool that was to become TextTest. We turned up on the first day for a workshop about "testing in XP", and Geoff was immediately controversial by saying that he didn't do any unit testing, only this weird text-based testing thing using log comparison. He said he found it so successful that he used it instead of both the XP practices of functional and unit testing. I remember several people being quite dismissive of his ideas.
Later in the conference, Kent Beck made a particular effort to talk to us and we took our picture standing by our poster. Apparently he had been asking people to try to be inclusive and friendly to us after the somewhat negative reaction to our ideas. I think he wanted the newly-forming XP community to be welcoming and to embrace diversity of opinion.

So now I should turn this around and look instead to the future. I'd love it if even half the people I've mentioned in this post found time in their diaries to come to Madrid in May for XP2011. I wouldn't want them to come alone though, there are so many fantastic and inspirational people who have joined the ever-expanding agile community since 2002.
I am every bit as keen now as Kent was then to see that the agile community embraces newcomers, and that the XP conference should provide a space where researchers and practitioners can freely discuss the state of the art. I hope we'll make new friends and business contacts, learn loads, and have fun. Would you like to join us there?
Friday, 3 December 2010
Django
Last night at GothPy we had a play with Django, a web application framework for Python. I'm fairly familiar with Rails, so it was interesting to see a different take on solving the same kinds of problems.
I downloaded Django for the first time when preparing for the meeting, and spent about a day going through the tutorial and trying stuff out. At the meeting were a few people who have used Django before, notably Mikko Hellsing, who has worked with it daily for several years.
It was so much easier learning the tool from people who knew it than by reading the documentation. Constant code review and real time answering of questions is just brilliant for learning.
At the meeting we decided to implement a very very simple web application, similar to the one that Johannes Brodwall performed as a Kata at XP2010 together with Ivar Nilsen. He calls it "Java EE Spike Kata" since he does it in Java with no particular web frameworks, just what comes with Java. (There is a video of him doing it on his blog, and sample solution here on github).
I thought we should be able to implement the same little application in any web framework, and it might be interesting to see differences, so I though we should try doing it in Django. It just involves two pages. One page "Add User" which lets you create a new user and save it to the database, and another page "Search User" which lets you search for users, and presents results. So the scenario is to create a user, search for them, and see they are returned.
When I work on a problem in Rails I usually start with a Cucumber scenario for the feature, and I discovered there is a python version of Cucumber called Lettuce. We could have course have just used Cucumber with python, but given the big "WARNING - Experimental" notice Aslak wrote on this page, I thought we could give Lettuce a try.
So at the meeting we all worked together with one laptop and a projector, (me at the keyboard), and we started with a Lettuce scenario. We implemented step definitions using Django's test Client, which is a kind of headless browser that understands how to instrument a Django application. Then we spent a couple of hours writing Django code together until the scenario was all green.
The code we ended up with isn't much to write home about, but I've put it up on github here.
What we learned from this exercise
Of course since I know Rails much better, I found it interesting to compare the two web frameworks. Django seems similar in many ways. It was dead easy to get up and running, it gives you a basic structure for your code, and separates the model from the presentation layer.
The O-R mapping looks quite similar to ActiveRecord in the way you declare model classes backed by tables in the db. The presentation layer seems to have a different philosophy from Rails though. The html view part is rather loosely coupled to your application, and doesn't allow you to embed real python code in it, just basic control structures.
You hook up the html to the controller code using url regular expression matching. I was a little confused about exactly how was supposed to work, since what I considered controller code was put in a file called "views.py". Most of the code we wrote ended up in here, and I feel a bit unhappy with it. It seems to be a mixture of stuff at all levels of abstraction. The Django Form objects we used seemed quite powerful though, and reduced the amount of code we had to write.
The biggest difference I noticed compared with Rails was how explicit Python is about where stuff comes from. You always have to declaratively import or pass stuff before you can use it, so I found it straightforward to follow the connections and work out which code was executed and where it came from. I think that is because of Python's philosophy of strict namespaces, which Ruby doesn't have so much of.
I also liked the way Django encourages you to structure a larger web application into a lot of independent smaller ones, and lets you include and re-use other people's small apps. Rails has plugins too of course, but I thought Django's way made it seem very natural to contribute and re-use code.
Comparing Lettuce to Cucumber, they look almost the same, (by design). One small difference I found was that Cucumber step definitions don't care if you write "Given", "When" or "Then" in front of them, whereas Lettuce did. So I had steps like this:
where the first step passed and the second step was reported as unimplemented by Lettuce. So Lettuce need a little more work to be really usable.
I was also pretty disappointed by the Django test client for implementing test steps. It seemed to interact with pages at an abstraction layer lower than I am used to - at the level of making post and get requests and parsing html as a dom. I missed Capybara and its DSL for interacting with web pages. I couldn't find any equivalent. I probably should have turned to Selenium directly, but since we had no client side javascript it seemed overkill. (Francisco Souza has written about using Lettuce with Selenium compared with the Django test client here).
When it comes to unit-level testing, Django provides an extension to the normal unittest tool that comes with python (unittest was originally based on JUnit). We didn't do much with it at the session, and it seemed to work fine. It's nothing like RSpec though, and I miss that expressiveness and structure for my tests whenever I work in Python.
Overall
All in all it was fun to look at Django with a group and to get some really helpful comments and insights from people who know it far better than I do. The Kata we chose seemed to work ok, but I should really do it again in Rails since I spent the whole time comparing Django with Rails in my head, not Django with Johannes' Java code :-)
My conclusions are basically that Django looks like a good alternative to Rails. It would take time to learn, and surely has strengths and weaknesses I can't really evaluate from one short session looking at it. However, I'd fairly sure I'd have to do some work improving the testing tools if I was going to be happy working with it for real.
I downloaded Django for the first time when preparing for the meeting, and spent about a day going through the tutorial and trying stuff out. At the meeting were a few people who have used Django before, notably Mikko Hellsing, who has worked with it daily for several years.
It was so much easier learning the tool from people who knew it than by reading the documentation. Constant code review and real time answering of questions is just brilliant for learning.
At the meeting we decided to implement a very very simple web application, similar to the one that Johannes Brodwall performed as a Kata at XP2010 together with Ivar Nilsen. He calls it "Java EE Spike Kata" since he does it in Java with no particular web frameworks, just what comes with Java. (There is a video of him doing it on his blog, and sample solution here on github).
I thought we should be able to implement the same little application in any web framework, and it might be interesting to see differences, so I though we should try doing it in Django. It just involves two pages. One page "Add User" which lets you create a new user and save it to the database, and another page "Search User" which lets you search for users, and presents results. So the scenario is to create a user, search for them, and see they are returned.
When I work on a problem in Rails I usually start with a Cucumber scenario for the feature, and I discovered there is a python version of Cucumber called Lettuce. We could have course have just used Cucumber with python, but given the big "WARNING - Experimental" notice Aslak wrote on this page, I thought we could give Lettuce a try.
So at the meeting we all worked together with one laptop and a projector, (me at the keyboard), and we started with a Lettuce scenario. We implemented step definitions using Django's test Client, which is a kind of headless browser that understands how to instrument a Django application. Then we spent a couple of hours writing Django code together until the scenario was all green.
The code we ended up with isn't much to write home about, but I've put it up on github here.
What we learned from this exercise
Of course since I know Rails much better, I found it interesting to compare the two web frameworks. Django seems similar in many ways. It was dead easy to get up and running, it gives you a basic structure for your code, and separates the model from the presentation layer.
The O-R mapping looks quite similar to ActiveRecord in the way you declare model classes backed by tables in the db. The presentation layer seems to have a different philosophy from Rails though. The html view part is rather loosely coupled to your application, and doesn't allow you to embed real python code in it, just basic control structures.
You hook up the html to the controller code using url regular expression matching. I was a little confused about exactly how was supposed to work, since what I considered controller code was put in a file called "views.py". Most of the code we wrote ended up in here, and I feel a bit unhappy with it. It seems to be a mixture of stuff at all levels of abstraction. The Django Form objects we used seemed quite powerful though, and reduced the amount of code we had to write.
The biggest difference I noticed compared with Rails was how explicit Python is about where stuff comes from. You always have to declaratively import or pass stuff before you can use it, so I found it straightforward to follow the connections and work out which code was executed and where it came from. I think that is because of Python's philosophy of strict namespaces, which Ruby doesn't have so much of.
I also liked the way Django encourages you to structure a larger web application into a lot of independent smaller ones, and lets you include and re-use other people's small apps. Rails has plugins too of course, but I thought Django's way made it seem very natural to contribute and re-use code.
Comparing Lettuce to Cucumber, they look almost the same, (by design). One small difference I found was that Cucumber step definitions don't care if you write "Given", "When" or "Then" in front of them, whereas Lettuce did. So I had steps like this:
Then I should see "results found"
And I should see "Name"
where the first step passed and the second step was reported as unimplemented by Lettuce. So Lettuce need a little more work to be really usable.
I was also pretty disappointed by the Django test client for implementing test steps. It seemed to interact with pages at an abstraction layer lower than I am used to - at the level of making post and get requests and parsing html as a dom. I missed Capybara and its DSL for interacting with web pages. I couldn't find any equivalent. I probably should have turned to Selenium directly, but since we had no client side javascript it seemed overkill. (Francisco Souza has written about using Lettuce with Selenium compared with the Django test client here).
When it comes to unit-level testing, Django provides an extension to the normal unittest tool that comes with python (unittest was originally based on JUnit). We didn't do much with it at the session, and it seemed to work fine. It's nothing like RSpec though, and I miss that expressiveness and structure for my tests whenever I work in Python.
Overall
All in all it was fun to look at Django with a group and to get some really helpful comments and insights from people who know it far better than I do. The Kata we chose seemed to work ok, but I should really do it again in Rails since I spent the whole time comparing Django with Rails in my head, not Django with Johannes' Java code :-)
My conclusions are basically that Django looks like a good alternative to Rails. It would take time to learn, and surely has strengths and weaknesses I can't really evaluate from one short session looking at it. However, I'd fairly sure I'd have to do some work improving the testing tools if I was going to be happy working with it for real.
Monday, 1 November 2010
KataMontyHall
I was at the local Ruby User Group last night, and I coded up KataMontyHall (see below) as a prepared Kata in front of the group. I got some great comments and feedback while I was coding, and I think the solution I ended up with was better than any I had created by myself during my practice sessions. I also got some new ideas about different approaches which I plan to try out and see if they improve the code even more.
Dave Hoover was visiting from the US, on his way to a speaking engagement at Öredev. He and I were both surprised to discover a common interest in the Monty Hall Dilemma. Dave has previously worked on it, and he showed us some code that he wrote 5 or 6 years ago when he was still learning Ruby. He even wrote an online version of the game when he was first learning ajax, that you can play yourself!
The Monty Hall Dilemma
There is a gameshow hosted by Monty Hall where contestants try to win a big prize, which is behind one of three doors. The contestant begins by choosing a door, but not opening it. Then Monty steps forward and opens one of the other doors. He reveals a goat (!). Then the contestant has the choice of either sticking with the door they have already chosen, or switching to the other unopened door. Whichever door the contestant decides on will be opened, and if they find the prize, they get to keep it. (I'm not sure what happens if they get the second goat!) So what's the best strategy? Stick or switch?
People are biased towards sticking with what they've chosen, and the vast majority of people stick with the door they choose originally. Intuitively there should be an equal chance of the prize being behind any of the three doors, so it shouldn't matter if you stick or switch. However, in this case, your intuition is wrong. You are twice as likely to win the prize if you switch to the other unopened door.
I am not the only one to think this result is incorrect, apparently famous mathematicians have also refused to accept it. What finally convinced them, was a computer simulation. Hmm I thought, that sounds like an interesting piece of code :-)
Pigeons are smarter than Humans
I heard about the Monty Hall Dilemma listening to the quirks and quarks podcast. Apparently humans are strange, because they don't learn to switch doors. Some researchers set up the same problem for pigeons, with birdseed behind one of the doors, and found the birds quickly learnt to switch doors. You can read the research for yourself!
So if you, like me, are keen to prove yourself more intelligent than a pigeon, why don't you spend some time writing a little program that simulates the game? If you get it right, your version of KataMontyHall should clearly show that switching doors is the best strategy :-)
Dave Hoover was visiting from the US, on his way to a speaking engagement at Öredev. He and I were both surprised to discover a common interest in the Monty Hall Dilemma. Dave has previously worked on it, and he showed us some code that he wrote 5 or 6 years ago when he was still learning Ruby. He even wrote an online version of the game when he was first learning ajax, that you can play yourself!
The Monty Hall Dilemma
There is a gameshow hosted by Monty Hall where contestants try to win a big prize, which is behind one of three doors. The contestant begins by choosing a door, but not opening it. Then Monty steps forward and opens one of the other doors. He reveals a goat (!). Then the contestant has the choice of either sticking with the door they have already chosen, or switching to the other unopened door. Whichever door the contestant decides on will be opened, and if they find the prize, they get to keep it. (I'm not sure what happens if they get the second goat!) So what's the best strategy? Stick or switch?
People are biased towards sticking with what they've chosen, and the vast majority of people stick with the door they choose originally. Intuitively there should be an equal chance of the prize being behind any of the three doors, so it shouldn't matter if you stick or switch. However, in this case, your intuition is wrong. You are twice as likely to win the prize if you switch to the other unopened door.
I am not the only one to think this result is incorrect, apparently famous mathematicians have also refused to accept it. What finally convinced them, was a computer simulation. Hmm I thought, that sounds like an interesting piece of code :-)
Pigeons are smarter than Humans
I heard about the Monty Hall Dilemma listening to the quirks and quarks podcast. Apparently humans are strange, because they don't learn to switch doors. Some researchers set up the same problem for pigeons, with birdseed behind one of the doors, and found the birds quickly learnt to switch doors. You can read the research for yourself!
So if you, like me, are keen to prove yourself more intelligent than a pigeon, why don't you spend some time writing a little program that simulates the game? If you get it right, your version of KataMontyHall should clearly show that switching doors is the best strategy :-)
Thursday, 7 October 2010
Agile Testing Days - day 2
On the wednesday of Agile Testing Days it was my turn to speak, and together with Fredrik Wendt we presented "The Coding Dojo as a forum for teaching Test Driven Development". The talk was mostly aimed at developers, and the basic idea is to encourage them to learn TDD, and that going to a coding dojo might be a good way of doing that.
Michael Bolton
The first keynote of the day was by Michael Bolton, someone I've never met before. His talk really made me think. He presented himself as an "agile skeptic", and had some criticisms of agile practices like automated unit and functional testing. He talked about testing as something that humans do - it is a "sapient activity" requiring an engaged brain. He said "Automated acceptance tests do not answer questions about value" - that is whether the software will be valuable to the people who are going to use it. He preferred to call them "rejection checks" - that is they check whether the software will be rejected, but do not test whether it will be accepted. Only a human can do that. Michael went on to question the large level of investment that agile teams make in these kinds of tests. He thought that effort could perhaps be better invested, when studies show only 6-15% of problems are regression issues.
Michael emphasized the role of testers in projects as "skilled investigators" who provide a service giving you information about a software product. He drew on an analogy with a film critic - they don't tell you if the film has passed or failed, they tell you about the attributes of the film that will appeal more or less to certain audiences.
I liked the way Michael talked about testing as an investigative activity, and the role of testers as intelligent humans. I think he undervalues the feedback developers get from automated functional tests though. Agile teams do a lot more refactoring than other kinds of teams, and I think without automated tests they would have a lot more than 6-15% regression issues. I do think it is useful to evaluate investment in automated tests against other investments though. Some of the tools we have, particularly for functional/system level testing are not very cost effective to use.
I also think that testers can only start doing a "film critic" kind of role when the software is largely free of basic defects. These should be caught before a skilled tester gets their hands on the software, by developers properly checking their work, and automating those checks.
Michael Bolton
The first keynote of the day was by Michael Bolton, someone I've never met before. His talk really made me think. He presented himself as an "agile skeptic", and had some criticisms of agile practices like automated unit and functional testing. He talked about testing as something that humans do - it is a "sapient activity" requiring an engaged brain. He said "Automated acceptance tests do not answer questions about value" - that is whether the software will be valuable to the people who are going to use it. He preferred to call them "rejection checks" - that is they check whether the software will be rejected, but do not test whether it will be accepted. Only a human can do that. Michael went on to question the large level of investment that agile teams make in these kinds of tests. He thought that effort could perhaps be better invested, when studies show only 6-15% of problems are regression issues.
Michael emphasized the role of testers in projects as "skilled investigators" who provide a service giving you information about a software product. He drew on an analogy with a film critic - they don't tell you if the film has passed or failed, they tell you about the attributes of the film that will appeal more or less to certain audiences.
I liked the way Michael talked about testing as an investigative activity, and the role of testers as intelligent humans. I think he undervalues the feedback developers get from automated functional tests though. Agile teams do a lot more refactoring than other kinds of teams, and I think without automated tests they would have a lot more than 6-15% regression issues. I do think it is useful to evaluate investment in automated tests against other investments though. Some of the tools we have, particularly for functional/system level testing are not very cost effective to use.
I also think that testers can only start doing a "film critic" kind of role when the software is largely free of basic defects. These should be caught before a skilled tester gets their hands on the software, by developers properly checking their work, and automating those checks.
Wednesday, 6 October 2010
Agile Testing Days - first conference day
Yesterday, Geoff gave his talk about agile GUI testing. For anyone who missed it, here is a video of him giving roughly the same talk earlier this year at Europython. Gojko Adzic has also blogged about what he said, which is exactly the kind of feedback we came to this conference for. In his post Gojko explains Geoff’s testing approach, and seems quietly positive about it, at least compared to the “sine of death” you get with other UI test automation tools. His conclusion that it looked more suitable for legacy code than greenfield development is a little uncomfortable though. We think it works there too :-)
Today I’m giving my talk about teaching Test Driven Development via Coding Dojos. I’m looking forward to some feedback from the community about that. In the meantime I’ve written a bit about the three keynote talks we listened to yesterday.
Lisa Crispin
The day started with a keynote from Lisa Crispin titled “Agile Defect Management”. The overall message was to “lower the bar!” and aim to reduce defect count as far as possible, even to the point where a defect tracking software becomes superfluous. There was a lot of talk about whether such a tool was needed, and in what situations, and she gave a good overview of the state of the art of thinking in this area.
This was a good talk, with audience involvement, by someone who knows what they are talking about. The thing is I have higher expectations from a keynote. I expect to come away inspired and challenged, with some new insight to take back to my daily life. For me, this talk didn’t really deliver that. Lisa concentrated too much on the specific question of whether to use an electronic defect tracking tool or not, and didn’t sufficiently put that question in to the wider context given in the title of the talk “agile defect management”. I was disappointed to find nothing really original or surprising in what Lisa said.
Linda Rising
This was a good talk to hold straight after lunch when everyone is a bit sleepy. Linda spoke very amusingly on the subject “Deception and Estimation: How we Fool Ourselves”. She began by inviting us to see this as “the weird talk” of the conference, and that she was going to go through some of the latest scientific research in the area of cognition and psychology and hoped to relate that to why we have such trouble making good estimates in the context of a software project.
A self-confessed scientific amateur, she stated up front that she wouldn’t provide references to the research she mentioned, although she could give them to you if you emailed her and asked. Linda then proceeded to relate a series of amusing anecdotes designed to illustrate how irrational and over-optimistic people can be. (Markus Gärtner has blogged about what they all were). Towards the end of the talk, Linda began to relate all this to the subject of estimation, and told a story about some conference where she met people who were trying to apply scientific methods, statistics and data mining to the problem of improving estimates in software projects. In my mind, a seemingly a rational response to the problem of irrational, over-optimistic people.
Linda then did what I saw as a complete about-turn in her argument. She quoted one proponent of this “scientific” approach as saying, “well we can’t just make up a number, can we?”. Well no, we can’t, Linda just spent the last half hour convincing us humans are over-optimistic and irrational, and you can’t trust them to make up numbers. Yet that seemed to be exactly what Linda then proposed we do in agile. The points about the way agile overcomes this natural human over-optimism by for example breaking down problems into thin slices, using the wisdom of the crowd and enforcing tight feedback cycles, all kind of got crammed in at the end with little or no explaination.
Quite apart from those specific criticisms of her argument, as someone with a scientific training I didn’t like the way Linda protrayed science and scientists. They initially appeared in Linda’s talk as white-coated oracles who make pronouncements of the truth. “80% of drivers think they are above average”. “You eat more at an all-you-eat buffet”. “Online daters lie about their age and weight”. She then attempted to shatter this illusion of scientific infalliability by quoting Planck, who pointed out that the scientific process doesn’t always proceed in an orderly manner, and sometimes new and better theories only really catch on when the older generation who invented the previous ones atually die off.
Yes, scientists are human too, and you do them a disservice when you only present their results as received truths, without references, and without explaining either the methods they used to reach the conclusions, or what they themselves think of the wider applicability of the results.
This could have been a far more interesting talk about actual recent research studies - what’s coming out of the latest brain imaging techniques, for exaple. Linda could also have spent more time explaining how agile works with human nature to provide better estimates and plans. For all that it made me laugh, all this talk left me with was a bunch of amusing anecdotes and an uneasy feeling that agile was anti-science.
Elisabeth Hendrickson
The last session of the day saw Elisabeth Hendrickson presenting “Lessons Learned from 100+ Simulated Agile Transitions”. With a huge amount of energy and panache, Elisabeth strode around the stage, explaining what happens in an exercise which she usually does with a group of 8-20 people over the course of a whole day. Within the framework of this simulation, she drew out stories and anecdotes to illustrate such diverse subjects as the Satir change model, how physical layout affects communication, the difference between status meetings and communication meetings, and tests as alignment tools.
This talk was definitely the highlight of my day. Elisabeth took some things I kind of knew about, and made me think about them in a different light, from a different angle, and in a new context. I was challenged to go back to my standup meetings and make sure they really are about communication, and that my task board really does make status visible. I have a additional way of explaining ATDD to people - in terms of aligning developers and other stakeholders and getting them moving in the same direction.
Having said all that, I do have a criticism (are you surprised?!). Elisabeth released her slides under the creative commons license, but she does not release the details of her simulation. This would effectively prevent anyone else from running it. I think this is rather like a tool vendor who presents a new testing approach, which by the way, you can’t use without either buying their tool, or spending a large amount of time and money developing your own version. Those kinds of talks don’t tend to get accepted at this kind of conference.
I was disappointed that Elisabeth didn’t release her simulation materials, and I’m not sure why she doesn’t want to. She is obviously a fantastic agile coach and facilitator, and has more invitations to speak than she has time or inclination to accept. It would surely only enhance her reputation to make the agile transition simulation game materials available.
Update: I talked to Elisabeth afterwards about her materials, and she related a story about another independent consultant she knows, who arrived at a client site ready to do a simulation exercise that he had designed, only to discover the participants had done the exact same exercise the week before with a different consultant! The other consultant had just taken the material without permission or acknowledgement. Elisabeth doesn't want to end up in the same situation, and I can understand that. She did say she could release more information about the simulation though, enough that you could understand how it is designed, and perhaps build your own similar one. I think that would be a reasonable compromise. I just felt slightly cheated after her keynote - I wanted to look at this simulation, poke at it, see how it works and understand why she could use it to generate so many great insights into agile transitions.
Tuesday, 5 October 2010
Tutorial with Lisa Crispin at Agile Testing Days
I’m at Agile Testing Days this week, and yesterday I attended a tutorial with Lisa Crispin. I’ve never actually met her before, although I have read many of her articles, and the book she wrote together with Janet Gregory, “Agile Testing”. It’s an important book, covering in some detail the role of testers in agile teams, with lots of practical advice and anecdotes from real life.
So I was very interested to meet Lisa and hear what she had to say. She had lots of general advice and war stories about what kinds of tools are useful in an agile setting. From all the new insights and thoughts I gathered from the tutorial, there were two stories that I’d like to share with you here.
The Whole team decides
Lisa’s main message was that automated testing tool choice is a whole team decision, since everyone on an agile team will be affected. She told a story about when she joined a team of Java programmers and persuaded them to try Watir for web testing - a tool that lets you write tests in Ruby. Although the developers agreed to this and were initially keen to learn Ruby, it became clear after a while that they just weren’t comfortable with it, and Lisa found she just didn’t get the help she needed when extending and maintaining the tests. They switched to a tool where the tests were written in Java and things worked much better.
That depressed me a little, I have to say. I’d personally much rather be writing Ruby than Java! Someone else chipped in with another story though. On his team they were also developing a system in Java, with the difference that the developers were very keen to learn Groovy. They had started writing tests using it, and it was working very well. It made writing tests more fun, since they got to learn a language they were interested in. The test automation work was less effort than expected, since they felt much more productive in Groovy than Java. I guess the difference is that the developers were motivated to learn the new language because they had chosen it.
You can do ATDD with GUI testing tools
Lisa told an interesting story about GUI testing. She said she was working on some new features and realized that the only way to test them was was via a GUI testing tool. She was at first very skeptical that they would be able to do Acceptance Test Driven Development with a GUI tool - the GUI hadn’t been written yet, so how could they use this tool to write tests?
In the end she said it turned out really well. They worked from GUI mockups of the new features, and wrote tests with placeholders. When the test scripts needed to interact with GUI elements that didn’t exist yet, she just wrote them in terms of what she’d like there to be there, based on the mockups. When the programmers came to implement the GUI, they could fill in the placeholders and quickly get the new tests running.
This was encouraging since it’s basically the way you work with PyUseCase too. A criticism we get sometimes is that since PyUseCase is a capture-replay tool, you can’t use it to define the tests before the GUI exists - a problem if you’re trying to do Acceptance Test Driven Development. Our experience matches Lisa’s though - you can define the test in general terms, with placeholders, and parts that won’t execute at all at first. Some parts of the test of course can be recorded from the existing GUI. As the GUI is extended for the new feature, gradually you replace the placeholders with executable statements until the whole test passes.
And now for the rest of the conference...
Geoff is giving a talk this morning about PyUseCase and TextTest as part of the main Agile Testing Days conference. We’d really like to get some feedback from experienced testers. It’s a different approach to capture-replay that most people here, like Lisa, will not have seen before. There are lots of other interesting talks and things going on too, and I hope to find time to blog a little more about the conference later in the week.
So I was very interested to meet Lisa and hear what she had to say. She had lots of general advice and war stories about what kinds of tools are useful in an agile setting. From all the new insights and thoughts I gathered from the tutorial, there were two stories that I’d like to share with you here.
The Whole team decides
Lisa’s main message was that automated testing tool choice is a whole team decision, since everyone on an agile team will be affected. She told a story about when she joined a team of Java programmers and persuaded them to try Watir for web testing - a tool that lets you write tests in Ruby. Although the developers agreed to this and were initially keen to learn Ruby, it became clear after a while that they just weren’t comfortable with it, and Lisa found she just didn’t get the help she needed when extending and maintaining the tests. They switched to a tool where the tests were written in Java and things worked much better.
That depressed me a little, I have to say. I’d personally much rather be writing Ruby than Java! Someone else chipped in with another story though. On his team they were also developing a system in Java, with the difference that the developers were very keen to learn Groovy. They had started writing tests using it, and it was working very well. It made writing tests more fun, since they got to learn a language they were interested in. The test automation work was less effort than expected, since they felt much more productive in Groovy than Java. I guess the difference is that the developers were motivated to learn the new language because they had chosen it.
You can do ATDD with GUI testing tools
Lisa told an interesting story about GUI testing. She said she was working on some new features and realized that the only way to test them was was via a GUI testing tool. She was at first very skeptical that they would be able to do Acceptance Test Driven Development with a GUI tool - the GUI hadn’t been written yet, so how could they use this tool to write tests?
In the end she said it turned out really well. They worked from GUI mockups of the new features, and wrote tests with placeholders. When the test scripts needed to interact with GUI elements that didn’t exist yet, she just wrote them in terms of what she’d like there to be there, based on the mockups. When the programmers came to implement the GUI, they could fill in the placeholders and quickly get the new tests running.
This was encouraging since it’s basically the way you work with PyUseCase too. A criticism we get sometimes is that since PyUseCase is a capture-replay tool, you can’t use it to define the tests before the GUI exists - a problem if you’re trying to do Acceptance Test Driven Development. Our experience matches Lisa’s though - you can define the test in general terms, with placeholders, and parts that won’t execute at all at first. Some parts of the test of course can be recorded from the existing GUI. As the GUI is extended for the new feature, gradually you replace the placeholders with executable statements until the whole test passes.
And now for the rest of the conference...
Geoff is giving a talk this morning about PyUseCase and TextTest as part of the main Agile Testing Days conference. We’d really like to get some feedback from experienced testers. It’s a different approach to capture-replay that most people here, like Lisa, will not have seen before. There are lots of other interesting talks and things going on too, and I hope to find time to blog a little more about the conference later in the week.
Friday, 24 September 2010
Coding Dojo Survey Results
A little while ago, Fredrik Wendt and I put together a little survey and sent it to all the people we know who have attended coding dojo meetings here in Göteborg. There are several groups in the city which run these kinds of meetings from time to time. We wanted to know what kinds of things people are learning from practicing code katas in a group, and get some feedback and comments to help us to develop the groups we run.
The survey got 29 responses - thankyou to everyone who participated! I was very encouraged to see that the overwhelming majority - 90% - said they would recommend the dojo to other people who wanted to improve their programming skills. There were lots of comments too - I won't include them all - but I particularly liked:

Fredrik and I set up JDojo@Gbg about a year ago, as an free coding dojo for Java programmers, sponsored by Iptor. We advertized it as a taught course - 5 sessions, once a month, come and learn TDD. We ran it twice together, and now Fredrik is continuing it together with Ola Berg.
The second sort of coding dojo going on in the town is various language user groups. It must be four years since I pestered Niclas Nilsson and CJ that we should do code Katas at Got.rb (Göteborg Ruby User Group). Inspired by the success of that group, and together with Andrew Dalke and Johan Lindberg, I set up GothPy (Gothenburg Python User Group) about two years ago. More recently, Jonas Nicklas set up Got.js (Göteborg javascript user group) and Jörgen Lundberg set up Scala Geats (Göteborg Scalaenthusiaster). So there are several small, language specific groups that meet and do dojo evenings occasionally, interspersed with other activities.
The third kind of coding dojo meetings going on is where people run them internally at their employer, which lots of people do from time to time. In addition, Fredrik and I are both facilitating these kinds of groups at clients, as part of our work coaching teams and encouraging them to be more agile.
I was pleased that people from all these sorts of groups filled in the survey, and that many people had been to more than one kind.
Most of the survey respondents had been to 4 or 5 dojo meetings:

We asked several questions about perceived skill level before and after participation in dojo meetings. We wanted to know what people thought they were learning, basically.

As you can see, people were fairly good at the programming language in question before the dojo(s), and only reported marginal improvements, 0.3 on average, on a five point scale.

When it comes to the IDE used in the dojo, again, we are looking at a modest improvement, also 0.3 on a five point scale.

Using Mock Objects is a topic that doesn't always come up in dojo meetings, I personally have certainly had more of a focus on classic TDD. The feedback shows that people didn't feel they were that good at it before the meetings, and not that much better afterwards - an average 0.5 increase on a 5 point scale. From some of the comments, I think this is an area to focus on more in future. To that end, we're having a GothPy meeting next week looking at Mockist TDD :-)

Refactoring is an essential part of Test Driven Development, and in fact any modern programmer's toolbox. I was pleased to see that people thought the dojo had helped them to improve this skill too - 0.5 on a five point scale.

So it looks like going to a dojo encourages you to write unit tests more often - 0.6 (on a five point scale) more often on average.

This result is the most pleasing to me, since I think TDD is such an important skill, and it can be so difficult to get going with. People are moving from a low level of skill up to a medium level of skill - a whole 1 point (on a five point scale) on average! No-one is claiming to be a TDD expert yet though, I will have to repeat the survey in a few years and see if anyone is brave enough to claim that by then ;-)
Fredrik and I are off to Agile Testing Days in a week or so, where we'll be presenting a bit about what we've been doing at these various groups, and what we recommend for others starting their own coding dojos. We've learnt a lot by running these meetings, and had fun too. Hopefully these survey results might encourage you to find a coding dojo and improve your programming skills!

The survey got 29 responses - thankyou to everyone who participated! I was very encouraged to see that the overwhelming majority - 90% - said they would recommend the dojo to other people who wanted to improve their programming skills. There were lots of comments too - I won't include them all - but I particularly liked:
"Dojos make me relive the joy of red-green-refactor”
“you learn a lot from each other at these meetings”
“... planting seeds that have improved me as a programmer and a problem solver”
“I have started to think in terms of TDD”
The first question asked people which dojo(s) they had been to.

Fredrik and I set up JDojo@Gbg about a year ago, as an free coding dojo for Java programmers, sponsored by Iptor. We advertized it as a taught course - 5 sessions, once a month, come and learn TDD. We ran it twice together, and now Fredrik is continuing it together with Ola Berg.
The second sort of coding dojo going on in the town is various language user groups. It must be four years since I pestered Niclas Nilsson and CJ that we should do code Katas at Got.rb (Göteborg Ruby User Group). Inspired by the success of that group, and together with Andrew Dalke and Johan Lindberg, I set up GothPy (Gothenburg Python User Group) about two years ago. More recently, Jonas Nicklas set up Got.js (Göteborg javascript user group) and Jörgen Lundberg set up Scala Geats (Göteborg Scalaenthusiaster). So there are several small, language specific groups that meet and do dojo evenings occasionally, interspersed with other activities.
The third kind of coding dojo meetings going on is where people run them internally at their employer, which lots of people do from time to time. In addition, Fredrik and I are both facilitating these kinds of groups at clients, as part of our work coaching teams and encouraging them to be more agile.
I was pleased that people from all these sorts of groups filled in the survey, and that many people had been to more than one kind.
Most of the survey respondents had been to 4 or 5 dojo meetings:
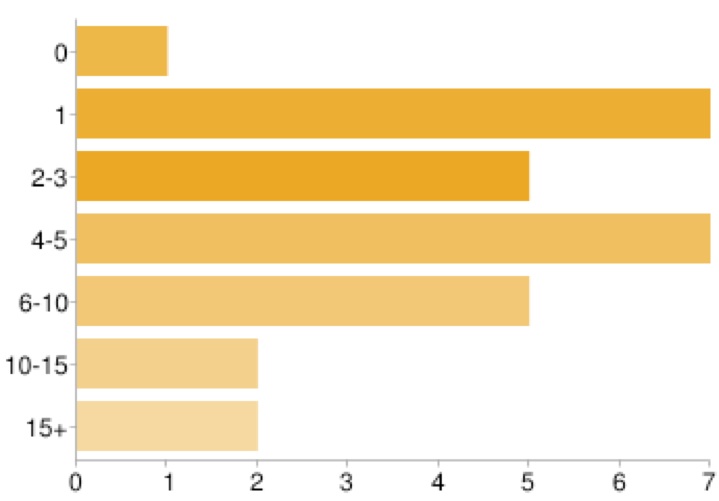
We asked several questions about perceived skill level before and after participation in dojo meetings. We wanted to know what people thought they were learning, basically.

As you can see, people were fairly good at the programming language in question before the dojo(s), and only reported marginal improvements, 0.3 on average, on a five point scale.

When it comes to the IDE used in the dojo, again, we are looking at a modest improvement, also 0.3 on a five point scale.

Using Mock Objects is a topic that doesn't always come up in dojo meetings, I personally have certainly had more of a focus on classic TDD. The feedback shows that people didn't feel they were that good at it before the meetings, and not that much better afterwards - an average 0.5 increase on a 5 point scale. From some of the comments, I think this is an area to focus on more in future. To that end, we're having a GothPy meeting next week looking at Mockist TDD :-)

Refactoring is an essential part of Test Driven Development, and in fact any modern programmer's toolbox. I was pleased to see that people thought the dojo had helped them to improve this skill too - 0.5 on a five point scale.

So it looks like going to a dojo encourages you to write unit tests more often - 0.6 (on a five point scale) more often on average.

This result is the most pleasing to me, since I think TDD is such an important skill, and it can be so difficult to get going with. People are moving from a low level of skill up to a medium level of skill - a whole 1 point (on a five point scale) on average! No-one is claiming to be a TDD expert yet though, I will have to repeat the survey in a few years and see if anyone is brave enough to claim that by then ;-)
Fredrik and I are off to Agile Testing Days in a week or so, where we'll be presenting a bit about what we've been doing at these various groups, and what we recommend for others starting their own coding dojos. We've learnt a lot by running these meetings, and had fun too. Hopefully these survey results might encourage you to find a coding dojo and improve your programming skills!
Saturday, 19 June 2010
What to do next
I had fun for a few months programming Ruby at eLabs, but now I'm moving on*. What exactly I'll be doing next is not entirely clear. My plan, at least initially, is to work as an independent consultant specializing in automated testing and agile coaching. I'd also like to do some contract Ruby or Python programming. Hopefully I will find customers who are willing to hire me to do those things on a part-time basis, or with short term contracts, so I can do a mixture.
I have a long term dream to build some kind of product around PyUseCase and TextTest. I really believe in the approach Geoff has built for testing rich client python GUIs, and I'd like to see if it could be adapted for testing web applications. I have some ideas I'd like to try out, but I'll need to find real customers with real applications and problems to try them out on. I'm hoping that will be possible through the agile testing consulting that I'll be doing.
I'd also like to develop the idea of the coding dojo as a forum for teaching Test Driven Development and related agile engineering practices. I'm certain there is more that could be done to help people to get going with these skills. I'm looking into what courses are currently offered by local training providers, and hoping to both teach and develop those courses. I'm also working on my own formal training course based around the JDojo@Gbg meetings I led last year.
As you may have noticed from previous posts, I really enjoy going to conferences, and often speak at them. I don't expect that to change much :-) Geoff and I are both scheduled to speak at Agile Testing Days in Berlin in October, which I am really looking forward to. It'll be a chance for us to learn from some of the best in our industry, and share some of our ideas. Geoff's testing tools are developing all the time, and I'll be talking about what we've learnt from the many dojo meetings going on in Göteborg. I'll be speaking together with my friend and former colleague Fredrik Wendt, a stalwart member of GothPy and assistant leader of JDojo@Gbg.
So it's an exciting time for me, and I have several activities lined up to get me going with my new business. I'm also hoping to find a bit more time to spend writing articles for this blog. We'll see if I succeed!
* eLabs is a very young company with only about 8 employees, and after I agreed to join CJ and his team back in January the company strategy changed a little. After I started in March, my role didn't work out the way I'd anticipated. CJ and I had a good talk about it, and I think it's with no hard feelings on either side that I left the company at the end of June.
I have a long term dream to build some kind of product around PyUseCase and TextTest. I really believe in the approach Geoff has built for testing rich client python GUIs, and I'd like to see if it could be adapted for testing web applications. I have some ideas I'd like to try out, but I'll need to find real customers with real applications and problems to try them out on. I'm hoping that will be possible through the agile testing consulting that I'll be doing.
I'd also like to develop the idea of the coding dojo as a forum for teaching Test Driven Development and related agile engineering practices. I'm certain there is more that could be done to help people to get going with these skills. I'm looking into what courses are currently offered by local training providers, and hoping to both teach and develop those courses. I'm also working on my own formal training course based around the JDojo@Gbg meetings I led last year.
As you may have noticed from previous posts, I really enjoy going to conferences, and often speak at them. I don't expect that to change much :-) Geoff and I are both scheduled to speak at Agile Testing Days in Berlin in October, which I am really looking forward to. It'll be a chance for us to learn from some of the best in our industry, and share some of our ideas. Geoff's testing tools are developing all the time, and I'll be talking about what we've learnt from the many dojo meetings going on in Göteborg. I'll be speaking together with my friend and former colleague Fredrik Wendt, a stalwart member of GothPy and assistant leader of JDojo@Gbg.
So it's an exciting time for me, and I have several activities lined up to get me going with my new business. I'm also hoping to find a bit more time to spend writing articles for this blog. We'll see if I succeed!
* eLabs is a very young company with only about 8 employees, and after I agreed to join CJ and his team back in January the company strategy changed a little. After I started in March, my role didn't work out the way I'd anticipated. CJ and I had a good talk about it, and I think it's with no hard feelings on either side that I left the company at the end of June.
Tuesday, 25 May 2010
Programmer Conferences are like Games
Why are there so few women programmers? That's a big question. How about a related one that's slightly smaller: Why do so few women go to programmer conferences?
Nordic Ruby on Twitter
Nordic Ruby was clearly appreciated by many of its attendees. See tweets like this:
ronge: #nordicruby - best conference ever, looking forward meeting you all next year ! Lots of food for thoughts. Really sad it's over.
skanev: #nordicruby was just awesome. Thank you guys
walming: Got so much inspiration. Big thanks @elabs for #nordicruby conference.
Very few Women
What I also noticed was, that of around 100 delegates, only 2 were women*.
I have to say, I go to a lot of conferences, which gives me plenty to compare it to. In addition to Nordic Ruby, in the past year I have been to: Scottish Ruby Conference, Scandinavian Developer Conference, JFokus, Smidig, Europython and XP2009. In general, I really enjoy conferences, and none of those I've mentioned had a huge proportion of females. Nordic Ruby was not exceptional in that respect. However, although I enjoyed Nordic Ruby, it does not feature in my all-time favourite list. I'll come to why in a minute. A lot of things about the conference were very good, of course. Some of the talks were excellent, and the venues, food and parties were absolutely top knotch.
The format of of the conference was 30 minute talks (all on one track) interspersed with 30-120 minute breaks. The last session of each day was open and any attendee could give a short "lightning" talk, and many people did so. Every speaker, lightning or otherwise, had a large audience, since there was nothing else on the programme.
Hampton Catlin's talk - the two kinds of Games
My favourite talk was one by Hampton Catlin, talking about how to make applications attractive to their users. He talked a bit about the different kinds of games that people prefer. Perhaps I can expand this idea to explain why I don't rate Nordic Ruby as highly as some of the other attendees clearly did.
Hampton explained that computer games lie on a scale from Male-Oriented to Female-Oriented. They are called by those names because your physical gender is a good predictor of which sort you will prefer. (He stressed that you should keep in mind that people are complex, defy easy categorization, and a given individual could have preferences anywhere on the scale.)
The Male-Oriented game will let you score points and rank yourself against opponents. The Female-Oriented game will let you build supportive social networks with collaborators, and become admired by your peers. Hampton said that most computer games are Male-Oriented. He highlighted some exceptions, including Farmville, which is a popular game on Facebook. In fact, he said Facebook itself can be seen as a Female-Oriented game.
Programmer Conferences are like Games
This got me thinking about the Nordic Ruby conference. If Facebook can be seen as a game, can you see a conference that way too? Do attendees play for "score" and "rank"? Is the programmer's conference game so Male-Oriented that most women just aren't interested in playing?
The Conference as a Male-Oriented Game
If a programmer conference is a Male-Oriented Game, it will provide you with opportunities to improve your rank and score compared to other attendees. For example, giving a talk will let you show off the cool software project(s) you have created/contributed to. You can improve your rank by criticising other people's code, and contrasting it with the beauty of your own. You can also score "geek points" by making gratuitous references to obscure programming languages, advanced mathematics and classic sci-fi films.
Your overall conference success is measured by how many people subsequently download your open source projects, and how many followers you gain on Twitter.
The Conference as a Female-Oriented Game
If a programmer conference is a Female-Oriented Game, it will provide you with opportunities to form supportive social networks and gain admiration. Lecture-style talks aren't so good for that, so the conference will schedule sessions for attendees to have conversations with each other, and collaborate. The conference programme will raise discussion topics that interest attendees, and encourage idea sharing. There may be organized group sessions where you share programming-related problems, pool your ideas and collectively come up with strategies to move forwards. You will gain admiration by being insightful, charming and subtly drawing people's attention to your open source projects, while also being admiring of others' projects.
Your overall conference success is measured by how many people subsequently contribute to your open source projects, and how many friendly messages you get on Twitter.
Who Won Nordic Ruby?
Ok, I'm stretching the analogy rather, (!) but I'd say the Nordic Ruby conference game was a little too Male-Oriented for my liking. The focus of the programme was on lecture-style talks, and, put it this way, the speakers made way too many references to Star Wars! There were long breaks, which gave many opportunities for conversation, but there were no formal network-building activities. There was lots of time for chatting, but no mechanism to draw people together around, say, a discussion topic, or a collaborative coding exercise.
The conferences I have enjoyed most have involved relatively few lecture-style talks, and largely comprised of workshops, coding dojos, tutorials, conversation corners and open space discussions. Next week I'm going to XP2010 (which will be my seventh XP conference :-D), and it's the first ever GothPyCon this Saturday. At both I am organizing coding dojo sessions - collaborative excercises in collective learning and mutual appreciation. Bring on the Female-Oriented conference games!
* There was also two other females there, but neither are programmers.
Nordic Ruby on Twitter
Nordic Ruby was clearly appreciated by many of its attendees. See tweets like this:
ronge: #nordicruby - best conference ever, looking forward meeting you all next year ! Lots of food for thoughts. Really sad it's over.
skanev: #nordicruby was just awesome. Thank you guys
walming: Got so much inspiration. Big thanks @elabs for #nordicruby conference.
Very few Women
What I also noticed was, that of around 100 delegates, only 2 were women*.
I have to say, I go to a lot of conferences, which gives me plenty to compare it to. In addition to Nordic Ruby, in the past year I have been to: Scottish Ruby Conference, Scandinavian Developer Conference, JFokus, Smidig, Europython and XP2009. In general, I really enjoy conferences, and none of those I've mentioned had a huge proportion of females. Nordic Ruby was not exceptional in that respect. However, although I enjoyed Nordic Ruby, it does not feature in my all-time favourite list. I'll come to why in a minute. A lot of things about the conference were very good, of course. Some of the talks were excellent, and the venues, food and parties were absolutely top knotch.
The format of of the conference was 30 minute talks (all on one track) interspersed with 30-120 minute breaks. The last session of each day was open and any attendee could give a short "lightning" talk, and many people did so. Every speaker, lightning or otherwise, had a large audience, since there was nothing else on the programme.
Hampton Catlin's talk - the two kinds of Games
My favourite talk was one by Hampton Catlin, talking about how to make applications attractive to their users. He talked a bit about the different kinds of games that people prefer. Perhaps I can expand this idea to explain why I don't rate Nordic Ruby as highly as some of the other attendees clearly did.
Hampton explained that computer games lie on a scale from Male-Oriented to Female-Oriented. They are called by those names because your physical gender is a good predictor of which sort you will prefer. (He stressed that you should keep in mind that people are complex, defy easy categorization, and a given individual could have preferences anywhere on the scale.)
The Male-Oriented game will let you score points and rank yourself against opponents. The Female-Oriented game will let you build supportive social networks with collaborators, and become admired by your peers. Hampton said that most computer games are Male-Oriented. He highlighted some exceptions, including Farmville, which is a popular game on Facebook. In fact, he said Facebook itself can be seen as a Female-Oriented game.
Programmer Conferences are like Games
This got me thinking about the Nordic Ruby conference. If Facebook can be seen as a game, can you see a conference that way too? Do attendees play for "score" and "rank"? Is the programmer's conference game so Male-Oriented that most women just aren't interested in playing?
The Conference as a Male-Oriented Game
If a programmer conference is a Male-Oriented Game, it will provide you with opportunities to improve your rank and score compared to other attendees. For example, giving a talk will let you show off the cool software project(s) you have created/contributed to. You can improve your rank by criticising other people's code, and contrasting it with the beauty of your own. You can also score "geek points" by making gratuitous references to obscure programming languages, advanced mathematics and classic sci-fi films.
Your overall conference success is measured by how many people subsequently download your open source projects, and how many followers you gain on Twitter.
The Conference as a Female-Oriented Game
If a programmer conference is a Female-Oriented Game, it will provide you with opportunities to form supportive social networks and gain admiration. Lecture-style talks aren't so good for that, so the conference will schedule sessions for attendees to have conversations with each other, and collaborate. The conference programme will raise discussion topics that interest attendees, and encourage idea sharing. There may be organized group sessions where you share programming-related problems, pool your ideas and collectively come up with strategies to move forwards. You will gain admiration by being insightful, charming and subtly drawing people's attention to your open source projects, while also being admiring of others' projects.
Your overall conference success is measured by how many people subsequently contribute to your open source projects, and how many friendly messages you get on Twitter.
Who Won Nordic Ruby?
Ok, I'm stretching the analogy rather, (!) but I'd say the Nordic Ruby conference game was a little too Male-Oriented for my liking. The focus of the programme was on lecture-style talks, and, put it this way, the speakers made way too many references to Star Wars! There were long breaks, which gave many opportunities for conversation, but there were no formal network-building activities. There was lots of time for chatting, but no mechanism to draw people together around, say, a discussion topic, or a collaborative coding exercise.
The conferences I have enjoyed most have involved relatively few lecture-style talks, and largely comprised of workshops, coding dojos, tutorials, conversation corners and open space discussions. Next week I'm going to XP2010 (which will be my seventh XP conference :-D), and it's the first ever GothPyCon this Saturday. At both I am organizing coding dojo sessions - collaborative excercises in collective learning and mutual appreciation. Bring on the Female-Oriented conference games!
* There was also two other females there, but neither are programmers.
Friday, 30 April 2010
Python and Ruby and small methods
I've been working full time in Ruby now for about a month, and I think I'm beginning to get the hang of it. In many ways it's not so different from Python.
I took some of the code I talked about struggling with in my last post, and set about translating it into Python. I wanted to see if the bugs were more obvious in a language I was more familiar with. Unfortunately before I was finished with the translation, my machine died and refused to restart, complaining about a disk error... so I may well have lost all my work. (ARRRGH!!) Anyway, before that happened, I was getting the feeling that the bugs weren't very obvious, even in a language I knew better.
What I did find though, was that it was quite hard to make the methods as short in Python as they were in Ruby. I could make them as short, the language has the necessary features to do it, but when I did so, they just stopped looking like good Python to me.
The other thing that I found was that RSpec lets you write really readable and well organized tests. Translating them into unittest made them just a travesty of their former selves.
I've just listened to this talk by Gary Bernhardt, who is experienced in both Python and Ruby, and who has clearly thought quite hard about these kinds of issues and knows both languages very well. He has even tried to write a RSpec clone for Python, called Mote. (He says himself that it isn't as good as RSpec, and that it is because Python lacks blocks, and won't let him monkeypatch core classes).
Anyway, about half way through the talk, Gary shows this code example, first in Python:
Then the equivalent code in Ruby:
Gary makes the point that the Ruby code is easier to read - you can follow it from top to bottom and see what it does. The thing is, I don't think many people would write code like that in Python. I might write it more like this:
This code is four statements long, rather than one, and has two local variables ("objs" and "names") which the other two code snippets lack. In real code, you would probably be able to come up with rather more descriptive names, drawn from the problem domain. When I compare this code with the Ruby, I don't think it is any less readable. The filter(lambda x: x, objs) is not as nice as the Ruby call to "compact", but on the other hand, I think the two additional local variables make it clearer what is going on.
I'm wondering whether the trouble I was having locating bugs in these small methods was because they were cramming so much into one statement, and almost completely lacking in local variables. That seems to be the Ruby way of doing things - maybe I will just get used to it and learn to read it just as well eventually? I guess I am going to find out!
Anyway, I'm really hoping the friendly support technicians manage to save the contents of my hard disk, I want to use the code in an exercise at the upcoming Gothenburg Python Conference - GothPyCon. I am hoping to run a workshop where half the room gets the buggy code with small methods, and the other half gets the same code refactored into longer methods. You get half an hour to find the bugs, then swap to the other codebase and find them again. Then I was hoping to have a discussion about which codebase was easier to debug, and/or split into pairs and re-implement the code from scratch, and see if we could come up with other designs that solved the problem more elegantly and transparently.
If issues like this interest you - design, refactoring and testing -, I really hope you will come along!
I took some of the code I talked about struggling with in my last post, and set about translating it into Python. I wanted to see if the bugs were more obvious in a language I was more familiar with. Unfortunately before I was finished with the translation, my machine died and refused to restart, complaining about a disk error... so I may well have lost all my work. (ARRRGH!!) Anyway, before that happened, I was getting the feeling that the bugs weren't very obvious, even in a language I knew better.
What I did find though, was that it was quite hard to make the methods as short in Python as they were in Ruby. I could make them as short, the language has the necessary features to do it, but when I did so, they just stopped looking like good Python to me.
The other thing that I found was that RSpec lets you write really readable and well organized tests. Translating them into unittest made them just a travesty of their former selves.
I've just listened to this talk by Gary Bernhardt, who is experienced in both Python and Ruby, and who has clearly thought quite hard about these kinds of issues and knows both languages very well. He has even tried to write a RSpec clone for Python, called Mote. (He says himself that it isn't as good as RSpec, and that it is because Python lacks blocks, and won't let him monkeypatch core classes).
Anyway, about half way through the talk, Gary shows this code example, first in Python:
'\n'.join(obj.name
for obj in (
repository.retrieve(id)
for id in ids)
if obj)
Then the equivalent code in Ruby:
ids.map do |id|
repository.retrieve(id)
end.compact.map do |obj|
obj.name
end.join('\n')
Gary makes the point that the Ruby code is easier to read - you can follow it from top to bottom and see what it does. The thing is, I don't think many people would write code like that in Python. I might write it more like this:
objs = [repository.retrieve(id) for id in ids]
objs = filter(lambda x: x, objs)
names = [obj.name for obj in objs]
'\n'.join(names)
This code is four statements long, rather than one, and has two local variables ("objs" and "names") which the other two code snippets lack. In real code, you would probably be able to come up with rather more descriptive names, drawn from the problem domain. When I compare this code with the Ruby, I don't think it is any less readable. The filter(lambda x: x, objs) is not as nice as the Ruby call to "compact", but on the other hand, I think the two additional local variables make it clearer what is going on.
I'm wondering whether the trouble I was having locating bugs in these small methods was because they were cramming so much into one statement, and almost completely lacking in local variables. That seems to be the Ruby way of doing things - maybe I will just get used to it and learn to read it just as well eventually? I guess I am going to find out!
Anyway, I'm really hoping the friendly support technicians manage to save the contents of my hard disk, I want to use the code in an exercise at the upcoming Gothenburg Python Conference - GothPyCon. I am hoping to run a workshop where half the room gets the buggy code with small methods, and the other half gets the same code refactored into longer methods. You get half an hour to find the bugs, then swap to the other codebase and find them again. Then I was hoping to have a discussion about which codebase was easier to debug, and/or split into pairs and re-implement the code from scratch, and see if we could come up with other designs that solved the problem more elegantly and transparently.
If issues like this interest you - design, refactoring and testing -, I really hope you will come along!
Tuesday, 6 April 2010
Small methods, TDD and defects
Last week at Scottish Ruby Conference I chatted with Brian Marick about software design. The week before that, he had been in Göteborg for Scandinavian Developer Conference, and had spent a morning pair programming with Geoff on TextTest. I took the chance to ask Brian what he thought about text-based testing now that he had seen it in action.
Brian's view seems to be that text-based testing may be effective as a testing technique, but it just doesn't offer the design benefits you get with standard TDD. It doesn't give you guidance about small-scale design decisions, or intice you to structure your code into really small methods and classes. He thought the TextTest codebase wasn't bad, but that the methods were larger than he would prefer, some classes were doing too much, and some ideas were not expressed clearly.
I've previously read about this design ethic of having really really small classes and methods in Bob Martin's book "Clean Code". Bob recommends one or two line methods. In contrast, I believe Steve McConnell's "Code Complete" advocates methods small enough to fit comfortably on one screen. Geoff's design for TextTest seems to land at about 5 or 6 lines for a typical method, which is somewhere in between.
Brian said the main drawback of code structured largely into small classes and one and two line methods is that it is harder for people who are unfamiliar with the codebase to get to grips with it. You get lost in the trees, and can't easily get an overview of the forest. The big benefit is that people who are familiar with the code can potentially make sweeping improvements through very small, localized changes.
I've had the opportunity to work on this kind of codebase recently, and my experience hasn't been entirely positive. Just as Brian predicted, I've found it hard to get into the code and grasp what it is doing. All the methods are one or two lines, and call each other. My pair and I ended up creating a temporary file where we pasted a whole call chain of about 6 methods so we could see them all at once, and read them in the order they called each other. There were 3 defects hidden in that 15 or so lines of code, and it took us a day or so to identify and fix them all. Yet, the code had been TDD'd, and the methods were well named. On the surface it looked very good. It actually took me some time to convince myself that we genuinely had found a defect, and that we hadn't just misunderstood what the code was supposed to do.
The trouble seemed to stem from the fact that almost all the tests were for the "happy path" and there were several edge cases they never considered. Also, in one case the test had stubbed out the answer that one of the lower-level methods would return, and provided an answer the real code never gave. It took a long time for us to add missing tests for edge cases, and localize the defects to particular methods in the long call chain.
I'm very interested in whether we would have found it easier to find the defects if the code had been structured as two or three 5 line methods instead of 6 one and two line methods. I'm also interested if we would have found the issues more easily if the code had been built with text-based testing, with fewer, more coarse grained tests, and a few log statements printing key intermediate values. I'm considering getting the original versions of the files out of git and refactoring them to see how else they could have looked.
I don't want you to conclude that I am against building designs with really small methods, or TDD, or using stubs or anything like that. I think there is value in all these techniques, each can be done well or badly, and you make tradeoffs when you choose your approach. You still need design skills and testing skills, whether you're doing TDD or text-based testing. If Brian Marick had built TextTest the design might well have turned out differently. I don't know how much of that would have been because of his use of TDD, and how much because of his skill, and views on design.
I'm actually relishing the prospect of working on more code with very small methods, and using TDD to build on it. I've got loads to learn about software design and testing :-)
Brian's view seems to be that text-based testing may be effective as a testing technique, but it just doesn't offer the design benefits you get with standard TDD. It doesn't give you guidance about small-scale design decisions, or intice you to structure your code into really small methods and classes. He thought the TextTest codebase wasn't bad, but that the methods were larger than he would prefer, some classes were doing too much, and some ideas were not expressed clearly.
I've previously read about this design ethic of having really really small classes and methods in Bob Martin's book "Clean Code". Bob recommends one or two line methods. In contrast, I believe Steve McConnell's "Code Complete" advocates methods small enough to fit comfortably on one screen. Geoff's design for TextTest seems to land at about 5 or 6 lines for a typical method, which is somewhere in between.
Brian said the main drawback of code structured largely into small classes and one and two line methods is that it is harder for people who are unfamiliar with the codebase to get to grips with it. You get lost in the trees, and can't easily get an overview of the forest. The big benefit is that people who are familiar with the code can potentially make sweeping improvements through very small, localized changes.
I've had the opportunity to work on this kind of codebase recently, and my experience hasn't been entirely positive. Just as Brian predicted, I've found it hard to get into the code and grasp what it is doing. All the methods are one or two lines, and call each other. My pair and I ended up creating a temporary file where we pasted a whole call chain of about 6 methods so we could see them all at once, and read them in the order they called each other. There were 3 defects hidden in that 15 or so lines of code, and it took us a day or so to identify and fix them all. Yet, the code had been TDD'd, and the methods were well named. On the surface it looked very good. It actually took me some time to convince myself that we genuinely had found a defect, and that we hadn't just misunderstood what the code was supposed to do.
The trouble seemed to stem from the fact that almost all the tests were for the "happy path" and there were several edge cases they never considered. Also, in one case the test had stubbed out the answer that one of the lower-level methods would return, and provided an answer the real code never gave. It took a long time for us to add missing tests for edge cases, and localize the defects to particular methods in the long call chain.
I'm very interested in whether we would have found it easier to find the defects if the code had been structured as two or three 5 line methods instead of 6 one and two line methods. I'm also interested if we would have found the issues more easily if the code had been built with text-based testing, with fewer, more coarse grained tests, and a few log statements printing key intermediate values. I'm considering getting the original versions of the files out of git and refactoring them to see how else they could have looked.
I don't want you to conclude that I am against building designs with really small methods, or TDD, or using stubs or anything like that. I think there is value in all these techniques, each can be done well or badly, and you make tradeoffs when you choose your approach. You still need design skills and testing skills, whether you're doing TDD or text-based testing. If Brian Marick had built TextTest the design might well have turned out differently. I don't know how much of that would have been because of his use of TDD, and how much because of his skill, and views on design.
I'm actually relishing the prospect of working on more code with very small methods, and using TDD to build on it. I've got loads to learn about software design and testing :-)
Wednesday, 17 March 2010
Discussion on TDD at SDC2010
As I mentioned in my last post I chaired a fishbowl discussion at SDC2010 with title "Should a professional developer always use Test Driven Development?". I was delighted that the invited panelists Michael Feathers, Geoff Bache and Andrew Dalke all turned up, along with a few dozen other conference participants. As I predicted, we had a lively and interesting debate.
Michael half-jokingly complained that Bob Martin goes around making these controvertial statements all the time, which Michael then gets to go around defending. Michael has a much more conciliatory attitude than Bob, and his take was that every truly professional developer must have at least given TDD a good try and learnt the technique, even if they then decide not to use it.
Geoff's main point was that we need to widen the definition of TDD to include any process that involves checking in tests at the same time as the code, and not restrict it to just the classic Red-Green-Refactor style with tests in the same language as the code.
Michael was largely receptive to this view, or at least that the soundbite description of "never write any code until you have a failing test" probably was a bit too brief description to encompass the whole of TDD. He did argue though, that the classic TDD style leads to code with good design characteristics of high cohesion, loose coupling, small classes and methods etc, and that he had not found other design techniques which led to better code than TDD. He was not keen to move to a TDD approach without unit tests, and lose these benefits, even if they result in good tests.
Andrew argued that TDD is not sufficient by itself to produce a good suite of tests, and that there are other, better ways to produce these tests. Andrew pointed out that he had examined Fitnesse, a codebase that Bob Martin, (and some others), has created using TDD, and that he found several bugs, including security holes in it. Michael's counterargument was that with TDD, you get as good tests as you are capable of - if you are not skilled/aware of security issues, then you won't test for security holes, whatever process you use to create tests.
Another argument of Andrew's was that he often likes to write tests that he expects to pass, to verify that his code works as expected, for example that he has implemented an algorithm correctly. In the narrow definition of TDD, you are only allowed to write tests you expect to fail. Michael's take was that this was indeed a too narrow definition of TDD. He said that he frequently writes tests as a way of asking questions of his code, and this often leads to tests that pass straight away.
Some of the "audience" also stepped up to the microphones and joined in. Brian Marick pointed out that forcing yourself to write the test first was a very good way of ensuring you do actually write the test, instead of being lazy and just writing more code. The counter to that was along the lines of that there are other processes for arriving at a good test suite, which took different kinds of discipline. Andrew quoted the sqlite project, which boasts 100% branch coverage of their code by their test suite. Publishing your coverage figures and refusing to let them slip is a way of preventing developer laziness too.
Brian Marick wrote an article about coverage and tests over a decade ago, so he summarized it for us, which was interesting, but I think slightly beside the point. I think he was trying to argue that measuring coverage alone is not enough to guarantee you have a good test suite, but I don't think that was what Andrew was trying to claim. Simply doing TDD is not a guarantee that you will end up with a good test suite either.
For me, the interesting outcome of the discussion was pointing out that the alternatives to TDD are not only "cowboy coding" or "test later, ie never", or "bad tests", but that there are other legitimate ways to come up with a good test suite, and professional developers may choose to use them instead of classic TDD. TDD is a discipline which all professional developers should perhaps have in their repertoire though. I think we agreed it is also a teaching aid for learning to write good tests.
Happily, we definitely all agree that creating a good automated test suite alongside code is important. The precise method a professional developer should always use to produce it was not agreed upon though.
Michael half-jokingly complained that Bob Martin goes around making these controvertial statements all the time, which Michael then gets to go around defending. Michael has a much more conciliatory attitude than Bob, and his take was that every truly professional developer must have at least given TDD a good try and learnt the technique, even if they then decide not to use it.
Geoff's main point was that we need to widen the definition of TDD to include any process that involves checking in tests at the same time as the code, and not restrict it to just the classic Red-Green-Refactor style with tests in the same language as the code.
Michael was largely receptive to this view, or at least that the soundbite description of "never write any code until you have a failing test" probably was a bit too brief description to encompass the whole of TDD. He did argue though, that the classic TDD style leads to code with good design characteristics of high cohesion, loose coupling, small classes and methods etc, and that he had not found other design techniques which led to better code than TDD. He was not keen to move to a TDD approach without unit tests, and lose these benefits, even if they result in good tests.
Andrew argued that TDD is not sufficient by itself to produce a good suite of tests, and that there are other, better ways to produce these tests. Andrew pointed out that he had examined Fitnesse, a codebase that Bob Martin, (and some others), has created using TDD, and that he found several bugs, including security holes in it. Michael's counterargument was that with TDD, you get as good tests as you are capable of - if you are not skilled/aware of security issues, then you won't test for security holes, whatever process you use to create tests.
Another argument of Andrew's was that he often likes to write tests that he expects to pass, to verify that his code works as expected, for example that he has implemented an algorithm correctly. In the narrow definition of TDD, you are only allowed to write tests you expect to fail. Michael's take was that this was indeed a too narrow definition of TDD. He said that he frequently writes tests as a way of asking questions of his code, and this often leads to tests that pass straight away.
Some of the "audience" also stepped up to the microphones and joined in. Brian Marick pointed out that forcing yourself to write the test first was a very good way of ensuring you do actually write the test, instead of being lazy and just writing more code. The counter to that was along the lines of that there are other processes for arriving at a good test suite, which took different kinds of discipline. Andrew quoted the sqlite project, which boasts 100% branch coverage of their code by their test suite. Publishing your coverage figures and refusing to let them slip is a way of preventing developer laziness too.
Brian Marick wrote an article about coverage and tests over a decade ago, so he summarized it for us, which was interesting, but I think slightly beside the point. I think he was trying to argue that measuring coverage alone is not enough to guarantee you have a good test suite, but I don't think that was what Andrew was trying to claim. Simply doing TDD is not a guarantee that you will end up with a good test suite either.
For me, the interesting outcome of the discussion was pointing out that the alternatives to TDD are not only "cowboy coding" or "test later, ie never", or "bad tests", but that there are other legitimate ways to come up with a good test suite, and professional developers may choose to use them instead of classic TDD. TDD is a discipline which all professional developers should perhaps have in their repertoire though. I think we agreed it is also a teaching aid for learning to write good tests.
Happily, we definitely all agree that creating a good automated test suite alongside code is important. The precise method a professional developer should always use to produce it was not agreed upon though.
Thursday, 4 March 2010
Should a professional developer always use TDD?
I'm really looking forward to Scandinavian Developer Conference, and in particular the fishbowl discussion I'll be moderating on the Tuesday at 10:30am. Presenting their views will be Michael Feathers, Andrew Dalke, and Geoff Bache, and the topic under discussion is the same as the title of this post: Should a professional developer always use TDD?
I've been enthusiastic about writing automated tests for my code since 2000 when I discovered eXtreme Programming, and started using JUnit. It's become a habit for me to write tests before code. Occasionly I decide not to, perhaps I am feeling lazy, or think a test would be too difficult to write. I find I usually regret it and end up writing a test afterwards anyway.
One of the things Bob Martin, (a colleague of Michael Feathers), says about TDD in his book "clean code", is that it is a matter of professionalism. Developers should be like doctors. Would you trust a doctor who didn't wash her hands because she didn't belive in it? Well, you shouldn't trust a developer who doesn't use TDD because she doesn't believe in it.
I've known Andrew Dalke since 2002, and we've worked together on and off since then. Recently he wrote this article criticising TDD. Andrew does not believe TDD is necessary for good development work to happen. Is he unprofessional? Far from it.
My experience of working with Andrew tells me that he is an excellent programmer, who produces high quality code and automated tests. However, the process by which he arrives at this code and tests is not TDD. Tests get written during development, but not in advance of the code they test. The tests do not in any way drive the design, in fact, he uses knowledge of the design of the code to inform what tests he writes.
Andrew says in his article "Once I have a good sketch of how the code is going to be, I often continue by filling in the details. At this point unit tests starts to be useful" he likens what he does to an XP spike solution, except that he does not throw away the spike code and start over when he starts adding tests.
The other person I know who has a complex relationship with TDD is my husband Geoff. Several years ago he was labelled a heretic and almost thrown out when he admitted to a room full of XP enthusiasts that he didn't write unit tests at all. Geoff does write tests - a lot of tests in fact - but they are not xUnit tests, and they don't drive the design of his code.
Geoff uses an approach he calls "text-based testing" which involves driving the program from the command line, (or some kind of script), and having his code write a plain text log file of what it is doing. A tool called TextTest picks up the log output and compares it to the saved version from a previous run. Differences are flagged as test failure.
It's a simple idea, but it is actually very effective and easy to use when you get the hang of it. The main advantage over ordinary TDD is that there is little or no code written per test, meaning less code to maintain overall. The fact that the tests are independent of the design of the code makes refactoring easier, and writing tests for legacy code relatively risk-free.
TDD is a bit different with the text-based approach though. Geoff thinks of what he does as TDD, but actually, only half of the test is nailed down in advance of the code - only the part that tells the program which features to exercise. The part that asserts that it did the right thing is simply recorded after the code is written.
So I expect a fascinating and lively discussion to ensue when I get these guys together! Perhaps you'll join us?
(Note: I wrote up the discussion in my next post)
I've been enthusiastic about writing automated tests for my code since 2000 when I discovered eXtreme Programming, and started using JUnit. It's become a habit for me to write tests before code. Occasionly I decide not to, perhaps I am feeling lazy, or think a test would be too difficult to write. I find I usually regret it and end up writing a test afterwards anyway.
One of the things Bob Martin, (a colleague of Michael Feathers), says about TDD in his book "clean code", is that it is a matter of professionalism. Developers should be like doctors. Would you trust a doctor who didn't wash her hands because she didn't belive in it? Well, you shouldn't trust a developer who doesn't use TDD because she doesn't believe in it.
I've known Andrew Dalke since 2002, and we've worked together on and off since then. Recently he wrote this article criticising TDD. Andrew does not believe TDD is necessary for good development work to happen. Is he unprofessional? Far from it.
My experience of working with Andrew tells me that he is an excellent programmer, who produces high quality code and automated tests. However, the process by which he arrives at this code and tests is not TDD. Tests get written during development, but not in advance of the code they test. The tests do not in any way drive the design, in fact, he uses knowledge of the design of the code to inform what tests he writes.
Andrew says in his article "Once I have a good sketch of how the code is going to be, I often continue by filling in the details. At this point unit tests starts to be useful" he likens what he does to an XP spike solution, except that he does not throw away the spike code and start over when he starts adding tests.
The other person I know who has a complex relationship with TDD is my husband Geoff. Several years ago he was labelled a heretic and almost thrown out when he admitted to a room full of XP enthusiasts that he didn't write unit tests at all. Geoff does write tests - a lot of tests in fact - but they are not xUnit tests, and they don't drive the design of his code.
Geoff uses an approach he calls "text-based testing" which involves driving the program from the command line, (or some kind of script), and having his code write a plain text log file of what it is doing. A tool called TextTest picks up the log output and compares it to the saved version from a previous run. Differences are flagged as test failure.
It's a simple idea, but it is actually very effective and easy to use when you get the hang of it. The main advantage over ordinary TDD is that there is little or no code written per test, meaning less code to maintain overall. The fact that the tests are independent of the design of the code makes refactoring easier, and writing tests for legacy code relatively risk-free.
TDD is a bit different with the text-based approach though. Geoff thinks of what he does as TDD, but actually, only half of the test is nailed down in advance of the code - only the part that tells the program which features to exercise. The part that asserts that it did the right thing is simply recorded after the code is written.
So I expect a fascinating and lively discussion to ensue when I get these guys together! Perhaps you'll join us?
(Note: I wrote up the discussion in my next post)
Sunday, 21 February 2010
developer-in-test role and tester role
In my current assignment, I'm taking the role of "developer-in-test". I'm working in a large distributed development project, which is building new functionality on a large existing codebase. In practice, I work closely with the developers in the project and build automated tests for subsystems that previously had only manual tests. The developers can use these tests to support their work, and add new tests as they build new features.
My background is basically as a developer, so I have been reading up on testing. I found "Lessons Learned in Software Testing" by Kaner, Pettichord and Bach very helpful, and "Agile Testing" by Lisa Crispin and Janet Gregory helpful and also very thorough. I find it interesting that the authors of the first book started out as developers and now classify themselves as testers, while Lisa and Janet apparently always have called themselves testers, although they clearly write a fair amount of code as part of their work.
Dave Nicolette recently made a blog post "Merging the developer and tester roles" where he argues that Tester is just a specialization of Developer in the agile world, like DBA (DataBaseAdministrator) is a specialization of Developer. He argues that agile teams need to be staffed with generalizing specialists. That means anyone can turn their hand to any task that is currently needed, while still having some tasks they perform with more skill than others.
I like Dave's viewpoint, it fits my experience. I can only write effective 2nd Quadrant tests, (business facing, support the team), if I understand what the developers need, and I do that best if I have done some development on that part of the system myself. To put it another way, I need to be just as competent at writing code as the other developers in the project I'm working in, but I also need additional skills to do with testing.
I like the term "developer-in-test" to describe a role writing and enabling 2nd Qudrant tests.
Having said all that, I'm not sure I agree with Dave that the Developer and Tester roles should always be merged. In my current assignment I'm also helping a group of testers, usability experts, technical writers and product owners to get going with exploratory testing. This testing falls into Q3 of the agile testing quadrants, and is quite different. You still need testing skills, but developer skills are mostly irrelevant. It's much more about understanding what the user is trying to achieve with the system, and how they view it.
I think there is a role for non-coding testers in Q3 testing. However, I don't think you'll get far with Q3 unless you have the other quadrants well covered with automated tests. So I think the majority of work for a tester in an agile environment is still going to involve test automation. Only the biggest projects will be able to afford to have non-coding testers.
My background is basically as a developer, so I have been reading up on testing. I found "Lessons Learned in Software Testing" by Kaner, Pettichord and Bach very helpful, and "Agile Testing" by Lisa Crispin and Janet Gregory helpful and also very thorough. I find it interesting that the authors of the first book started out as developers and now classify themselves as testers, while Lisa and Janet apparently always have called themselves testers, although they clearly write a fair amount of code as part of their work.
Dave Nicolette recently made a blog post "Merging the developer and tester roles" where he argues that Tester is just a specialization of Developer in the agile world, like DBA (DataBaseAdministrator) is a specialization of Developer. He argues that agile teams need to be staffed with generalizing specialists. That means anyone can turn their hand to any task that is currently needed, while still having some tasks they perform with more skill than others.
I like Dave's viewpoint, it fits my experience. I can only write effective 2nd Quadrant tests, (business facing, support the team), if I understand what the developers need, and I do that best if I have done some development on that part of the system myself. To put it another way, I need to be just as competent at writing code as the other developers in the project I'm working in, but I also need additional skills to do with testing.
I like the term "developer-in-test" to describe a role writing and enabling 2nd Qudrant tests.
Having said all that, I'm not sure I agree with Dave that the Developer and Tester roles should always be merged. In my current assignment I'm also helping a group of testers, usability experts, technical writers and product owners to get going with exploratory testing. This testing falls into Q3 of the agile testing quadrants, and is quite different. You still need testing skills, but developer skills are mostly irrelevant. It's much more about understanding what the user is trying to achieve with the system, and how they view it.
I think there is a role for non-coding testers in Q3 testing. However, I don't think you'll get far with Q3 unless you have the other quadrants well covered with automated tests. So I think the majority of work for a tester in an agile environment is still going to involve test automation. Only the biggest projects will be able to afford to have non-coding testers.
Sunday, 14 February 2010
XP2010 workshop and lightning talk
I've just heard that two of my proposals for XP2010 have been accepted, which means I will definitely be off to Trondheim in early June. I've heard Trondheim is very beautiful, and the XP conference it usually excellent, so I'm really looking forward to it. It will actually be my 8th XP conference!
I'm going to be running a half day workshop "Test Driven Development: Performing Art", which will be similar to the one I ran at XP2009, (which I blogged about here). I've put up a call for proposals on the codingdojo wiki, so do write to me if you're interested in taking part.
The other thing I'll be doing is a lightning talk "Making GUI testing productive and agile". This will basically be a brief introduction to PyUseCase with a little demo. Hopefully it will raise interest in this kind of approach.
Perhaps I'll see you there?
I'm going to be running a half day workshop "Test Driven Development: Performing Art", which will be similar to the one I ran at XP2009, (which I blogged about here). I've put up a call for proposals on the codingdojo wiki, so do write to me if you're interested in taking part.
The other thing I'll be doing is a lightning talk "Making GUI testing productive and agile". This will basically be a brief introduction to PyUseCase with a little demo. Hopefully it will raise interest in this kind of approach.
Perhaps I'll see you there?
Friday, 5 February 2010
code coverage and tests
At GothPy yesterday, Geoff talked about code coverage and tests. Geoff has spent a lot of his evenings lately working on PyUseCase, and getting the test coverage up to 100%, (statement coverage), a feat which he achieved last week. The evidence for this is available for all to see on the texttest site, (which is updated daily, btw, so if it is not green and 100% the day you read this post, then clearly Geoff had a bad day yesterday).
I have limited experience of using coverage statistics to evaluate my tests, so it was interesting to hear Geoff summarize his findings. He thought it had been well worth the effort to get coverage to 100%, he'd found some bugs, some dead code, and improved his design along the way. Actually, saying he has 100% coverage is a statement that needs qualification. The tool he's been using - coverage.py - has a feature whereby you can mark lines of code as # pragma: no cover, ie I don't want this line counted for coverage purposes. So he's marked 37 of 3242 lines like this.
The reason for excluding these lines is mostly practical - due to the nature of the tool you can't test it automatically when it is in "interactive" mode without physically pressing the buttons yourself - so automated tests for that part are impossible. Some excluded lines are for error cases which should never occur, but for which it would be useful to have a good error message if they ever did.
Overall, Geoff thinks coverage is very useful to help you to identify
Similarly, if your tests cover all your features and some code is not covered, maybe it's not that important code at all, and could be safely removed. Geoff's tests are not unit tests, they are testing the whole of PyUseCase, and that maybe makes a difference with this particular point. If I just had unit tests, and a piece of code wasn't covered, I'm not sure I could as easily infer that it wasn't needed as a part of a larger feature.
Refactoring opportunities can be identified from gaps in coverage too. The idea is that poorly tested code is a clue that it has other problems too. Perhaps you find two pieces of code are similar, and one copy has a gap in coverage. This could indicate they originate from copy-paste programming, and could be combined into one routine, with full test coverage.
Geoff had some tips for people who wanted to use coverage statistics to improve their tests.
Inspired by Geoff's talk, I spent some time today trying to get some coverage numbers for the code and tests I'm working on at present. Unfortunately it seemed to be a bit tricky to get the coverage tool to work. It's not python, of course, and that may have something to do with it. Hopefully I'll sort it out and be able to write a new blog post about my own experiences with coverage statistics sometime soon.
I have limited experience of using coverage statistics to evaluate my tests, so it was interesting to hear Geoff summarize his findings. He thought it had been well worth the effort to get coverage to 100%, he'd found some bugs, some dead code, and improved his design along the way. Actually, saying he has 100% coverage is a statement that needs qualification. The tool he's been using - coverage.py - has a feature whereby you can mark lines of code as # pragma: no cover, ie I don't want this line counted for coverage purposes. So he's marked 37 of 3242 lines like this.
The reason for excluding these lines is mostly practical - due to the nature of the tool you can't test it automatically when it is in "interactive" mode without physically pressing the buttons yourself - so automated tests for that part are impossible. Some excluded lines are for error cases which should never occur, but for which it would be useful to have a good error message if they ever did.
Overall, Geoff thinks coverage is very useful to help you to identify
- poorly tested areas of your code
- mistakes in your tests
- dead code
- refactoring opportunities
Similarly, if your tests cover all your features and some code is not covered, maybe it's not that important code at all, and could be safely removed. Geoff's tests are not unit tests, they are testing the whole of PyUseCase, and that maybe makes a difference with this particular point. If I just had unit tests, and a piece of code wasn't covered, I'm not sure I could as easily infer that it wasn't needed as a part of a larger feature.
Refactoring opportunities can be identified from gaps in coverage too. The idea is that poorly tested code is a clue that it has other problems too. Perhaps you find two pieces of code are similar, and one copy has a gap in coverage. This could indicate they originate from copy-paste programming, and could be combined into one routine, with full test coverage.
Geoff had some tips for people who wanted to use coverage statistics to improve their tests.
- Don’t design your tests around coverage. Write appropriate tests, and then measure coverage.
- This applies even when working with coverage results. See the coverage report as containing clues for new tests, not commands.
- Use “#pragma : no cover” in your code to be explicit about code that you decide not to try and cover. Review these periodically.
- Don’t be fanatical about absolute numbers. Commands like “Aim for at least 85% coverage” are counterproductive. (You get what you measure).
- It’s always good to increase feasible coverage. It’s sometimes better to spend your limited time on other things. But if you don’t measure, you can’t make that decision effectively.
Inspired by Geoff's talk, I spent some time today trying to get some coverage numbers for the code and tests I'm working on at present. Unfortunately it seemed to be a bit tricky to get the coverage tool to work. It's not python, of course, and that may have something to do with it. Hopefully I'll sort it out and be able to write a new blog post about my own experiences with coverage statistics sometime soon.
Wednesday, 27 January 2010
Domain Specific Languages for Selenium Tests
I gave this talk at JFokus this week in Stockholm. I thought people might be interested in a summary of my main points.
I've been using Selenium for web application testing for over a year now, on a couple of different projects. This talk is based on my experiences.
What is Selenium?
Selenium is actually an umbrella term for a suite of tools. The two tools in the suite I have been using are Selenium Remote Control (RC) ,which allows you to test your webapp as it runs in a broswer, from Java code., and Selenium IDE, which is a Firefox plugin that allows you to record tests.
Selenium's killer feature is that it allows you to test your app while it is running in a browser, with a real browser javascript engine. This is particularly important for web applications with a lot of javascript and ajax. Selenium is also actively maintained, with version 2.0 having recently arrived at alpha release status.
I showed a demo of how to write a test using Selenium IDE to record browser interaction, then pasting that into Java code. The test doesn't pass the first time you execute it, you have to tweak the code to replace xpaths with ids, and add a "wait" for the page to load at one point in the test. I find this is typical - Selenium IDE helps you to get started with your test, but there is still a lot of manual work to get it to pass.
The code you end up with is rather widget-oriented and low level, this is what I end up with in my example:
This is all very well, you can basically read what it is doing, (open the "New publisher" page, fill in a form, then check the user table displays correctly), but I think we can do better.
Agile Testing Theory
Brian Marick came up with this idea of "Testing Quadrants", which helps us to reason about what kinds of tests we need in an agile project. Selenium tests generally fall into the second quadrant - business facing tests that support the team. This implies they should be written in the language of the business, to help developers to understand what they are building. This is in contrast to the low-level, widget oriented script that selenium IDE produces.
It is better to discover a bug as soon after insertion as possible, and the faster the tests run, the more often you will run them. The usual rule of thumb says your tests must take less than a minute for you to run them as part of a TDD cycle, and less than 10 minutes for you to run them in the CI server. For a suite of selenium tests, even 10 minutes can be ambitious.
Selenium tests are fundamentally slow. They are slow because they run inside the browser using its javascript motor.
WebDriver
WebDriver (new in Selenium 2.0) uses a different model of interacting with your application under test. It uses the browser's api instead of its javascript motor. This means tests execute faster and more reliably, at the cost of supporting fewer browsers. In addition, WebDriver has a well thought out, clean api, and built in support for the PageObject pattern. Having said that, WebDriver is a very recent addition to selenium, and currently has poor or no integration with Selenium IDE and Selenium Grid.
the Page Object pattern
The PageObject pattern is a way of organizing your test code. It tells you to model your test code after the page structure of your application. The test I listed earlier could be rewritten using this pattern, and might look something like this:
Here we are using a data struct to hold the form data, which tells you quite obviously that a PublisherData has a name, address and contact person. Then we have the Page Object for the NewPublisherPage, which uses selenium to navigate to the relevant page in the constructor, then has methods which allow us to interact with that page. When we as it to "save", we navigate to a new page, in this case the ViewPublisherPage, which we can ask to validate the new publisher is displayed correctly.
This is an improvement over the original test in several ways. I think it is much more readable, we have a certain amount of type safety from the data struct, and if the page flow, or form data changes, there are obvious central places in the code to update all the tests. We can easily vary the form data in different tests in order to do data driven testing.
Scenario classes
However, in the application I've been working on, we havn't used this pattern in quite this way. The application uses a lot of frames and ajax, and a page based model didn't really fit. So we've been using the idea of "Scenario" classes instead of Page Objects. They fulfill the same purpose, but instead of modelling pages in your app, these classes group together domain actions, or services that your application provides. The Scenario classes hide all the details of how to use selenium to interact with the GUI and achieve an outcome a user is interested in. In this case, creating a publisher.
So with the PageObject or Scenario patterns, you could say that my tests are written in a kind of Domain Specific Language, in that they are written in terms close to the domain of the application they are testing. The trouble is, this is still Java code, and business people generally can't read Java. A more interesting DSL would enable communication between developers and business people.
This is where I turned to Fitnesse to help me. I found it pretty straightforward to put some Fitnesse tables over the top of this kind of Java code. Since the Java code is already organized in terms of the domain, it becomes natural to offer the same functionality in tables with meaningful names.
I chose Fitnesse because I wanted to try it out, but I think it would be equally easy to put Cucumber or Robot Framework or something like that on top, too. The whole point of these tools is that they allow you to easily write executable tests in a language anyone with knowledge of the domain can read. This is a huge benefit to developers when talking to business people.
Closing advice
Having said all this about how to make your Selenium tests more readable, robust and faster, I still find my Selenium test suite frustratingly slow and fragile (I havn't used WebDriver enough yet to know if that is the case there too). Compared to PyUseCase, it is in the dark ages. (Unfortunately PyUseCase has no support for web applications, so there's probably no point in mentioning it, actually. But it is a great tool!).
The difference between PageObjects and Scenario classes is not huge, but I like the latter, because they allow me to easily exchange Selenium for a WebService. My tests are written in terms of the services the application offers, and if I indeed implement those services as WebServices, I can call them directly from the tests. Using a WebService instead of selenium immediately makes my tests much faster and more robust.
The problem with testing against a WebService is the reason we chose Selenium in the first place - ajax and browsers are not covered.
So for web 2.0 application testing, I recommend both API tests and Selenium tests. Use Selenium to test the crucial parts of your GUI, but write most of your tests against some kind of WebService or API. Write your tests in terms a business user would understand, even in the Java code, and then it is easy to create a Domain Specific Language on top using another tool.
I've been using Selenium for web application testing for over a year now, on a couple of different projects. This talk is based on my experiences.
What is Selenium?
Selenium is actually an umbrella term for a suite of tools. The two tools in the suite I have been using are Selenium Remote Control (RC) ,which allows you to test your webapp as it runs in a broswer, from Java code., and Selenium IDE, which is a Firefox plugin that allows you to record tests.
Selenium's killer feature is that it allows you to test your app while it is running in a browser, with a real browser javascript engine. This is particularly important for web applications with a lot of javascript and ajax. Selenium is also actively maintained, with version 2.0 having recently arrived at alpha release status.
I showed a demo of how to write a test using Selenium IDE to record browser interaction, then pasting that into Java code. The test doesn't pass the first time you execute it, you have to tweak the code to replace xpaths with ids, and add a "wait" for the page to load at one point in the test. I find this is typical - Selenium IDE helps you to get started with your test, but there is still a lot of manual work to get it to pass.
The code you end up with is rather widget-oriented and low level, this is what I end up with in my example:
@Test
public void createNewPublisher() {
selenium.click("menuItemPNewPublisher");
selenium.waitForPageToLoad("30000");
selenium.type("name", "Disney");
selenium.type("address", "24 Stars Ave");
selenium.type("zipCode", "91210");
selenium.type("city", "Hollywood");
selenium.type("country", "USA");
selenium.type("contactPersonName", "Emily");
selenium.type("contactPersonEmail", "emily@test.com");
selenium.type("contactPersonPassword", "123456");
selenium.type("contactPersonRetypePassword", "123456");
selenium.click("save");
selenium.waitForPageToLoad("30000");
verifyEquals(selenium.getTable("Users.1.1"), "Emily");
}
This is all very well, you can basically read what it is doing, (open the "New publisher" page, fill in a form, then check the user table displays correctly), but I think we can do better.
Agile Testing Theory
Brian Marick came up with this idea of "Testing Quadrants", which helps us to reason about what kinds of tests we need in an agile project. Selenium tests generally fall into the second quadrant - business facing tests that support the team. This implies they should be written in the language of the business, to help developers to understand what they are building. This is in contrast to the low-level, widget oriented script that selenium IDE produces.
It is better to discover a bug as soon after insertion as possible, and the faster the tests run, the more often you will run them. The usual rule of thumb says your tests must take less than a minute for you to run them as part of a TDD cycle, and less than 10 minutes for you to run them in the CI server. For a suite of selenium tests, even 10 minutes can be ambitious.
Selenium tests are fundamentally slow. They are slow because they run inside the browser using its javascript motor.
WebDriver
WebDriver (new in Selenium 2.0) uses a different model of interacting with your application under test. It uses the browser's api instead of its javascript motor. This means tests execute faster and more reliably, at the cost of supporting fewer browsers. In addition, WebDriver has a well thought out, clean api, and built in support for the PageObject pattern. Having said that, WebDriver is a very recent addition to selenium, and currently has poor or no integration with Selenium IDE and Selenium Grid.
the Page Object pattern
The PageObject pattern is a way of organizing your test code. It tells you to model your test code after the page structure of your application. The test I listed earlier could be rewritten using this pattern, and might look something like this:
@Test
public void createNewPublisher() {
PublisherData newPublisher = new PublisherData("Disney")
.withAddress(
new AddressData("24 Stars Ave",
"91210", "Hollywood", "USA"))
.withContactPerson(
new UserData("Emily", "emily.bache@test.com",
"123456"));
NewPublisherPage page = new NewPublisherPage(selenium);
page.enterPublisherDetails(newPublisher);
ViewPublisherPage viewPage = (ViewPublisherPage)page.save();
viewPage.verifyPublisherDetails(newPublisher);
}
Here we are using a data struct to hold the form data, which tells you quite obviously that a PublisherData has a name, address and contact person. Then we have the Page Object for the NewPublisherPage, which uses selenium to navigate to the relevant page in the constructor, then has methods which allow us to interact with that page. When we as it to "save", we navigate to a new page, in this case the ViewPublisherPage, which we can ask to validate the new publisher is displayed correctly.
This is an improvement over the original test in several ways. I think it is much more readable, we have a certain amount of type safety from the data struct, and if the page flow, or form data changes, there are obvious central places in the code to update all the tests. We can easily vary the form data in different tests in order to do data driven testing.
Scenario classes
However, in the application I've been working on, we havn't used this pattern in quite this way. The application uses a lot of frames and ajax, and a page based model didn't really fit. So we've been using the idea of "Scenario" classes instead of Page Objects. They fulfill the same purpose, but instead of modelling pages in your app, these classes group together domain actions, or services that your application provides. The Scenario classes hide all the details of how to use selenium to interact with the GUI and achieve an outcome a user is interested in. In this case, creating a publisher.
Domain Specific Languages
@Test
public void createNewPublisher() {
PublisherData newPublisher = new PublisherData("Disney")
.withAddress(new AddressData("24 Stars Ave",
"91210", "Hollywood", "USA"))
.withContactPerson(
new UserData("Emily", "emily@test.com",
"123456"));
PublisherScenarios scenarios =
new PublisherScenarios(selenium);
scenarios.createPublisher(newPublisher);
scenarios.verifyPublisherDetails(newPublisher);
}
So with the PageObject or Scenario patterns, you could say that my tests are written in a kind of Domain Specific Language, in that they are written in terms close to the domain of the application they are testing. The trouble is, this is still Java code, and business people generally can't read Java. A more interesting DSL would enable communication between developers and business people.
This is where I turned to Fitnesse to help me. I found it pretty straightforward to put some Fitnesse tables over the top of this kind of Java code. Since the Java code is already organized in terms of the domain, it becomes natural to offer the same functionality in tables with meaningful names.
I chose Fitnesse because I wanted to try it out, but I think it would be equally easy to put Cucumber or Robot Framework or something like that on top, too. The whole point of these tools is that they allow you to easily write executable tests in a language anyone with knowledge of the domain can read. This is a huge benefit to developers when talking to business people.
Closing advice
Having said all this about how to make your Selenium tests more readable, robust and faster, I still find my Selenium test suite frustratingly slow and fragile (I havn't used WebDriver enough yet to know if that is the case there too). Compared to PyUseCase, it is in the dark ages. (Unfortunately PyUseCase has no support for web applications, so there's probably no point in mentioning it, actually. But it is a great tool!).
The difference between PageObjects and Scenario classes is not huge, but I like the latter, because they allow me to easily exchange Selenium for a WebService. My tests are written in terms of the services the application offers, and if I indeed implement those services as WebServices, I can call them directly from the tests. Using a WebService instead of selenium immediately makes my tests much faster and more robust.
The problem with testing against a WebService is the reason we chose Selenium in the first place - ajax and browsers are not covered.
So for web 2.0 application testing, I recommend both API tests and Selenium tests. Use Selenium to test the crucial parts of your GUI, but write most of your tests against some kind of WebService or API. Write your tests in terms a business user would understand, even in the Java code, and then it is easy to create a Domain Specific Language on top using another tool.
Subscribe to:
Posts (Atom)